


# 前端页面劫持和反劫持
作为一个优秀的工程师,仅仅会写代码时不够的,是时候了解一下安全相关的知识了,此次主要讲述一下前端常见的劫持
什么是网页劫持
当我们在手机上访问网页时,经常会看到一些不属于网页本身的内容,常见的是在网页中加入一些别人的广告,这种情况很明显是被劫持了
常见的页面劫持有:
- 点击劫持
- http 劫持
- DNS 劫持
- CDN 劫持
- 前端页面劫持
# 一、点击劫持
点击劫持(ClickJacking)是一种视觉上的欺骗手段。大概有两种方式:
- 是攻击者使用一个透明的 iframe,覆盖在一个网页上,然后诱使用户在该页面上进行操作,此时用户将在不知情的情况下点击透明的 iframe 页面;
- 是攻击者使用一张图片覆盖在网页,遮挡网页原有位置的含义。
# 1. iframe 覆盖及解决办法
假如我们在百度有个贴吧,想偷偷让别人关注它。于是我们准备一个页面:
<!DOCTYPE html>
<html>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<head>
<title>点击劫持</title>
<style>
html,
body,
iframe {
display: block;
height: 100%;
width: 100%;
margin: 0;
padding: 0;
border: none;
}
iframe {
opacity: 0;
filter: alpha(opacity=0);
position: absolute;
z-index: 2;
}
button {
position: absolute;
top: 315px;
left: 462px;
z-index: 1;
width: 72px;
height: 26px;
}
</style>
</head>
<body>
那些不能说的秘密
<button>查看详情</button>
<iframe src="http://tieba.baidu.com/f?kw=%C3%C0%C5%AE"></iframe>
</body>
</html>
网址传播出去后,用户手贱点击了查看详情后,其实就会点到关注按钮。这样贴吧就多了一个粉丝了。
使用一个 HTTP 头——X-Frame-Options。X-Frame-Options可以说是为了解决ClickJacking而生的,它有三个可选的值:
DENY:浏览器会拒绝当前页面加载任何 frame 页面;
SAMEORIGIN:frame 页面的地址只能为同源域名下的页面;
ALLOW-FROM origin:允许 frame 加载的页面地址;
PS:浏览器支持情况:
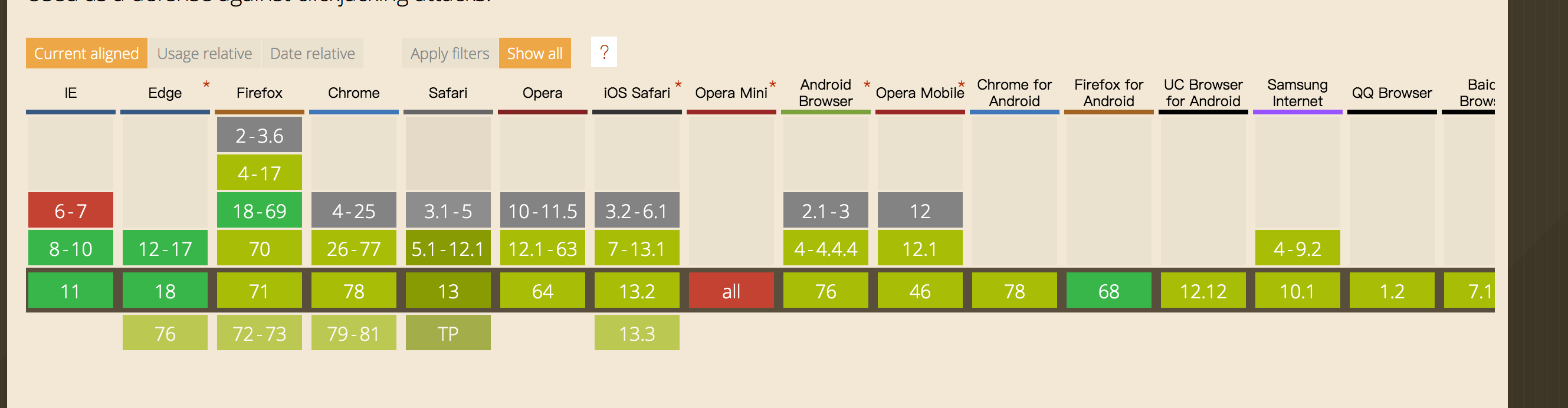
具体的设置方法:
Apache
Header always append X-Frame-Options SAMEORIGIN
nginx 配置:
add_header X-Frame-Options SAMEORIGIN;
# 2. 图片覆盖及解决办法
图片覆盖攻击(Cross Site Image Overlaying),攻击者使用一张或多张图片,利用图片的 style 或者能够控制的 CSS,将图片覆盖在网页上,形成点击劫持。当然图片本身所带的信息可能就带有欺骗的含义,这样不需要用户点击,也能达到欺骗的目的。
解决办法
在防御图片覆盖攻击时,需要检查用户提交的 HTML 代码中,img 标签的 style 属性是否可能导致浮出。
# 二、http 劫持
HTTP 劫持是在使用者与其目的网络服务所建立的专用数据通道中,监视特定数据信息,提示当满足设定的条件时,就会在正常的数据流中插入精心设计的网络数据报文,目的是让用户端程序解释“错误”的数据,并以弹出新窗口的形式在使用者界面展示宣传性广告或者直接显示某网站的内容。
比如:
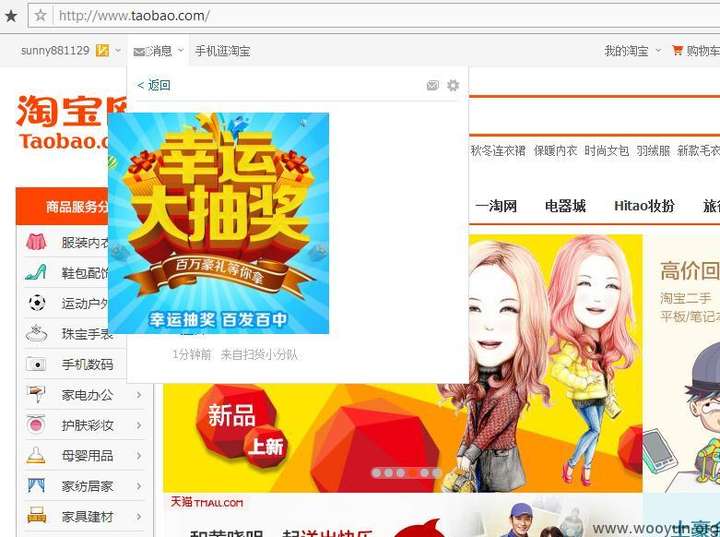
一般来说 HTTP 劫持主要通过下面几个步骤来做:
- 标识 HTTP 连接。在天上飞的很多连接中,有许多种协议,第一步做的就是在 TCP 连接中,找出应用层采用了 HTTP 协议的连接,进行标识
- 篡改 HTTP 响应体,可以通过网关来获取数据包进行内容的篡改
- 抢先回包,将篡改后的数据包抢先正常站点返回的数据包先到达用户侧,这样后面正常的数据包在到达之后会被直接丢弃

# 1. HTTP 劫持的手段
一般通用的方法都是插入静态脚本或者是 HTML Content,或者是将整体替换成 iframe,然后再在顶层的 iframe 上进行内容的植入
# 2. 防范 HTTP 劫持
# 事前加密
方法一:https
很大一部分 HTTP 劫持,主要的原因就是在传输数据时都是明文的,使用了 HTTPS 后,会在 HTTP 协议之上加上 TLS 进行保护,使得传输的数据进行加密,但是使用 HTTPS,一定要注意规范,必须要全站使用 HTTPS,否则只要有一个地方没有使用 HTTPS,明文传输就很有可能会被 HTTP 劫持了
但是相应的,全部使用 HTTPS,也会带来一些问题:
- 性能可能有所降低,因为多了 TLS 握手所带来的 2 次 RTT 延时(但是基于 HTTPS 之上的 HTTP2 可以更有效的提升性能)
- 由于运营商可能会使用 DNS 劫持,在 DNS 劫持之下,HTTPS 的服务完全用不了了,所以会导致白屏
方法二:加密代理
加密代理的原理就是在用户侧和目标 web 服务器之间增加一个代理服务器,在用户和代理之间会经过运营商的节点,这里使用各种加密手段保证安全,在代理服务器与 web 服务之间使用 HTTP 请求,只需确认代理与 web 服务之间不会被 HTTP 劫持就可以避开 HTTP 劫持
# 事中加密
拆分 HTTP 请求数据包
在 HTTP 劫持的步骤中,第一步是标记 TCP 连接,因此只要躲过了标识,那么后续的运营商篡改就不会存在了,有一种方式就是拆分 HTTP 请求
拆分数据包就是把 HTTP 请求的数据包拆分成多个,运营商的旁路设备由于没有完整的 TCP/IP 协议栈,所以就不会被标志,而目标 web 服务器是有完整的 TCP/IP 协议栈,能接收到的数据包拼成完整的 HTTP 请求,不影响服务
# 事后屏蔽
通过浏览器 Api,根据若干规则去匹配 DOM 中的节点,对匹配到的节点作拦截和隐藏
CSP(内容安全策略),DOM 事件监听等。
CSP 是浏览器附加的一层安全层,用于对抗跨站脚本与数据注入,运营商植入内容性质与数据注入类似,因此,可以用 CSP 对抗运营商劫持。通过在 HTTP 响应头或 meta 标签设置好规则,支持拦截和上报劫持信息的功能。
DOM 事件监听主要是监听DOMNodeInserted、DOMContentLoaded、DOMAttrModified、MutationObserver等事件,可以在前端 DOM 结构发生变化时触发回调,这时补充一些检测逻辑,即可判断是不是业务的正常 UI 逻辑,如果不是,即可认为是来自劫持
# 三、DNS 劫持
DNS 劫持即通过某种技术手段,篡改正确域名和 IP 地址的映射关系,使得域名映射到了错误的 IP 地址,因此可以认为 DNS 劫持是一种 DNS 重定向攻击。DNS 劫持通常可被用作域名欺诈,如在用户访问网页时显示额外的信息来赚取收入等;也可被用作网络钓鱼,如显示用户访问的虚假网站版本并非法窃取用户的个人信息
# 1. DNS 原理
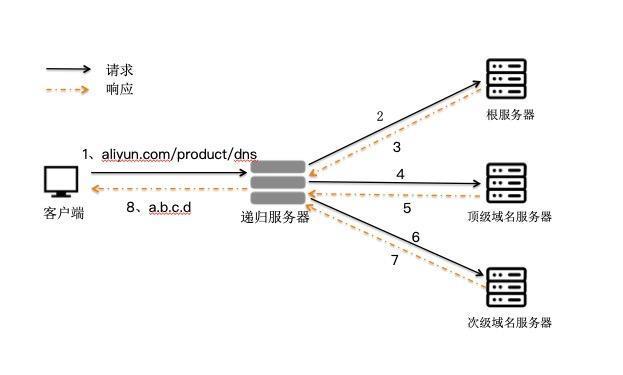
我们按照客户端侧--递归 DNS 服务器--权威 DNS 服务器的路径,将 DNS 劫持做如下分类:
本地DNS劫持和DNS解析路径劫持和篡改DNS权威记录。
# 2. 本地 DNS 劫持
客户端侧发生的 DNS 劫持统称为本地 DNS 劫持。本地 DNS 劫持可能是:
- 黑客通过木马病毒或者恶意程序入侵 PC,篡改 DNS 配置(hosts 文件,DNS 服务器地址,DNS 缓存等)。
- 黑客利用路由器漏洞或者破击路由器管理账号入侵路由器并且篡改 DNS 配置。
- 一些企业代理设备(如 Cisco Umbrella intelligent proxy)针对企业内部场景对一些特定的域名做 DNS 劫持解析为指定的结果。
# 3. DNS 解析路径劫持
DNS 解析过程中发生在客户端和 DNS 服务器网络通信时的 DNS 劫持统一归类为 DNS 解析路径劫持。通过对 DNS 解析报文在查询阶段的劫持路径进行划分,又可以将 DNS 解析路径劫持划分为如下三类.
- DNS 请求转发
- DNS 请求复制
- DNS 请求代答
- DNS 请求转发 通过技术手段(中间盒子,软件等)将 DNS 流量重定向到其他 DNS 服务器。
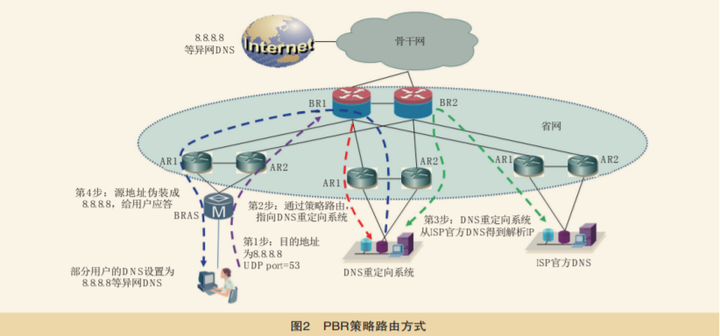
DNS 请求复制 利用分光等设备将 DNS 查询复制到网络设备,并先于正常应答返回 DNS 劫持的结果
DNS 请求代答 网络设备或者软件直接代替 DNS 服务器对 DNS 查询进行应答
# 4. 篡改 DNS 权威记录
篡改 DNS 权威记录 我们这里指的黑客非法入侵 DNS 权威记录管理账号,直接修改 DNS 记录的行为。
# 5. DNS 劫持应对策略
DNS 劫持在互联网中似乎已经变成了家常便饭,那么该如何应对各种层出不穷的 DNS 劫持呢?如果怀疑自己遇到了 DNS 劫持,首先要做的事情就是要确认问题
移动端可以安装一些 DNS 相关的测试工具进行排查:
- 安卓 ping & dns
- IOS IOS iNetTools
# 5. DNS 劫持防范
- 安装杀毒软件,防御木马病毒和恶意软件;定期修改路由器管理账号密码和更新固件。
- 选择安全技术实力过硬的域名注册商,并且给自己的域名权威数据上锁,防止域名权威数据被篡改。
- 选择支持 DNSSEC 的域名解析服务商,并且给自己的域名实施 DNSSEC。DNSSEC 能够保证递归 DNS 服务器和权威 DNS 服务器之间的通信不被篡改。阿里云 DNS 作为一家专业的 DNS 解析服务厂商,一直在不断完善打磨产品功能,DNSSEC 功能已经在开发中,不日就会上线发布。
- 在客户端和递归 DNS 服务器通信的最后一英里使用 DNS 加密技术,如 DNS-over-TLS,DNS-over-HTTPS 等
# 四、CDN 劫持
出于性能考虑,前端应用通常会把一些静态资源存放到 CDN(Content Delivery Networks)上面,例如 js 脚本和 style 文件。这么做可以显著提高前端应用的访问速度,但与此同时却也隐含了一个新的安全风险。如果攻击者劫持了 CDN,或者对 CDN 中的资源进行了污染,攻击者可以肆意篡改我们的前端页面,对用户实施攻击。
现在的 CDN 以支持 SRI 为荣,script 和 link 标签有了新的属性
integrity,这个属性是为了防止校验资源完整性来判断是否被篡改。它通过 验证获取文件的哈希值是否和你提供的哈希值一样来判断资源是否被篡改。
使用 SRI 需要两个条件:
- 是要保证 资源同域 或开启跨域,
- 是在
<script>中 提供签名 以供校验。
SRI 全称 Subresource Integrity - 子资源完整性,是指浏览器通过验证资源的完整性(通常从 CDN 获取)来判断其是否被篡改的安全特性。
通过给 link 标签或者 script 标签增加 integrity 属性即可开启 SRI 功能,比如:
<script
type="text/javascript"
src="//s.url.cn/xxxx/aaa.js"
integrity="sha256-xxx sha384-yyy"
crossorigin="anonymous"
></script>
integrity 值分成两个部分,第一部分指定哈希值的生成算法(sha256、sha384 及 sha512),第二部分是经过 base64 编码的实际哈希值,两者之间通过一个短横(-)分割。integrity 值可以包含多个由空格分隔的哈希值,只要文件匹配其中任意一个哈希值,就可以通过校验并加载该资源。上述例子中我使用了 sha256 和 sha384 两种 hash 方案。
备注:crossorigin="anonymous" 的作用是引入跨域脚本,在 HTML5 中有一种方式可以获取到跨域脚本的错误信息,首先跨域脚本的服务器必须通过
Access-Controll-Allow-Origin头信息允许当前域名可以获取错误信息,然后是当前域名的 script 标签也必须声明支持跨域,也就是 crossorigin 属性。link、img 等标签均支持跨域脚本。如果上述两个条件无法满足的话, 可以使用 try catch 方案。
# 1. 浏览器如何处理 SRI
- 当浏览器在
script或者link标签中遇到integrity属性之后,会在执行脚本或者应用样式表之前对比所加载文件的哈希值和期望的哈希值。 - 当脚本或者样式表的哈希值和期望的不一致时,浏览器必须拒绝执行脚本或者应用样式表,并且必须返回一个网络错误说明获得脚本或样式表失败。
# 2. 使用 SRI
通过使用 webpack 的 html-webpack-plugin 和 webpack-subresource-integrity 可以生成包含 integrity 属性 script 标签。
import SriPlugin from "webpack-subresource-integrity";
const compiler = webpack({
output: {
crossOriginLoading: "anonymous"
},
plugins: [
new SriPlugin({
hashFuncNames: ["sha256", "sha384"],
enabled: process.env.NODE_ENV === "production"
})
]
});
# 3. SRI 使用之:自定义 onerror
那么当 script 或者 link 资源 SRI 校验失败的时候应该怎么做呢?
比较好的方式是通过 script 的 onerror 事件,当遇到 onerror 的时候重新 load 静态文件服务器之间的资源:
<script
type="text/javascript"
src="//11.url.cn/aaa.js"
integrity="sha256-xxx sha384-yyy"
crossorigin="anonymous"
onerror="loadScriptError.call(this, event)"
onsuccess="loadScriptSuccess"
></script>
在此之前注入以下代码:
(function () {
function loadScriptError (event) {
// 上报
...
// 重新加载 js
return new Promise(function (resolve, reject) {
var script = document.createElement('script')
script.src = this.src.replace(/\/\/11.src.cn/, 'https://x.y.z') // 替换 cdn 地址为静态文件服务器地址
script.onload = resolve
script.onerror = reject
script.crossOrigin = 'anonymous'
document.getElementsByTagName('head')[0].appendChild(script)
})
}
function loadScriptSuccess () {
// 上报
...
}
window.loadScriptError = loadScriptError
window.loadScriptSuccess = loadScriptSuccess
})()
# 4. SRI 使用之:注入 onerror 事件
当然,由于项目中的 script 标签是由 webpack 打包进去的,所以我们要使用 script-ext-html-webpack-plugin 将 onerror 事件和 onsuccess 事件注入进去
const ScriptExtHtmlWebpackPlugin = require("script-ext-html-webpack-plugin");
module.exports = {
//...
plugins: [
new HtmlWebpackPlugin(),
new SriPlugin({
hashFuncNames: ["sha256", "sha384"]
}),
new ScriptExtHtmlWebpackPlugin({
custom: {
test: /\/*_[A-Za-z0-9]{8}.js/,
attribute: "onerror",
value: "loadScriptError.call(this, event)"
}
}),
new ScriptExtHtmlWebpackPlugin({
custom: {
test: /\/*_[A-Za-z0-9]{8}.js/,
attribute: "onsuccess",
value: "loadScriptSuccess.call(this, event)"
}
})
]
};
然后将 loadScriptError 和 loadScriptSuccess 两个方法注入到 html 中,可以使用 inline 的方式。
# 5. 如何判断发生 CDN 劫持?
方法就是再请求一次数据,比较两次得到文件的内容(当然不必全部比较),如果内容不一致,就可以得出结论了。
function loadScript (url) {
return fetch(url).then(res => {
if (res.ok) {
return res
}
return Promise.reject(new Error())
}).then(res => {
return res.text()
}).catch(e => {
return ''
})
比较两次加载的 script 是否相同
function checkScriptDiff(src, srcNew) {
return Promise.all([loadScript(src), loadScript(srcNew)])
.then(data => {
var res1 = data[0].slice(0, 1000);
var res2 = data[1].slice(0, 1000);
if (!!res1 && !!res2 && res1 !== res2) {
// CDN劫持事件发生
}
})
.catch(e => {
// ...
});
}
这里为什么只比较前 1000 个字符?因为通常 CDN 劫持者会在 js 文件最前面注入一些代码来达到他们的目的,注入中间代码需要 AST 解析,成本较高,所以比较全部字符串没有意义。如果你还是有顾虑的话,可以加上后 n 个字符的比较
# 6. 其他方法
应对流量劫持,前端能做哪些工作? (opens new window)
# 五、前端页面劫持
# 1. 跳转型劫持
跳转型劫持就是:用户输入地址 A,但是跳转到地址 B
解决办法 跳转型劫持如果用单纯靠 Web 页面进行检测比较困难,通常对比访问的 URL 是否是之前要访问的 URL,如果 URL 不一致,则记录上报。
# 2. 注入型劫持
注入型劫持:有别于跳转型型劫持,指通过在正常的网页中注入广告代码(js、iframe 等),实现页面弹窗提醒或者底部广告等,又分为下面三个小类:
- 注入 js 类劫持:在正常页面注入劫持的 js 代码实现的劫持
- iframe 类劫持:将正常页面嵌入 iframe 或者页面增加 iframe 页面
- 篡改页面类劫持:正常页面出现多余的劫持网页标签,导致页面整体大小发生变化
# 注入 js 劫持
注入 js 的方式可以通过
document.write或者直接改html代码片段等方式,给页面增加外链 js,为了做到更难检测,有些运营商会捏造一个不存在的 url 地址,从而不被过滤或者检测
解决办法
- 改写 document.write 方法
- 遍历页面 script 标签,给外链 js 增加白名单,不在白名单内 js 外链都上报
# iframe 类劫持
解决办法 检测是否被 iframe 嵌套。
这个通过比较parent对象,如果页面被嵌套,则parent!==window,要获取我们页面的 URL 地址,可以使用下面的代码:
function getParentUrl() {
var url;
if (parent !== window) {
try {
url = parent.location.href;
} catch (e) {
url = document.referrer;
}
}
return url;
}
# 特殊方法
前面提到类似电信捏造在白名单内的 js URL 和篡改页面内容的,我们用上面提到的方法检测不到这些信息,如果是在 APP 内,可以做的事情就比较多了,除了上面之外,还可以比较页面的content-length。当时手百的做法是:
在用户开始输入 query 的时候,APP 访问一个空白页面,页面内只有 html、title、head、body、script,而 script 标签内主要代码就是嗅探是否被劫持。因为一般劫持不会针对某个页面,而是针对整个网站域名,所以我们的空白页面也会被劫持。一旦被劫持,那么这么简单的页面结构就很容易做页面劫持分析,分析出来劫持手段就上报 case
function hiJackSniffer() {
var files = $.toArray(D.querySelectorAll("script[src]"));
var arr = [];
for (var i = 0, len = files.length; i < len; i++) {
files[i].src && arr.push(files[i].src);
}
if (arr.length) {
return sendImg(arr, 1);
}
arr = getParentUrl();
if (arr && arr.length) {
//被嵌入iframe
return sendImg([arr], 2);
}
if (D.documentElement.outerHTML.length > 4e3) {
var tmp = {};
var headjs = $.toArray(D.head.querySelectorAll("script"));
var unknownCode = [];
if (headjs.length) {
unknownCode = unknownCode.concat(
headjs
.map(function(v) {
return v.innerHTML;
})
.filter(function(v) {
return !!v;
})
);
}
var body = $.toArray(D.body.querySelectorAll("*"));
if (body.length > 1) {
unknownCode = unknownCode.concat(
body
.map(function(v) {
return v.outerHTML.split("\n").join("");
})
.filter(function(str) {
if (/^<script id="b">/.test(str)) {
return false;
}
return true;
})
);
}
return sendImg(unknownCode, 3);
}
sendImg([], 0);
}
这样做除了可以检测到多余的 js 外链,还可以检测出来篡改页面内容等 case。除了检测域名劫持之外,在用户输入 query 的时刻访问空白的页面也可以提前完成 DNS 解析,另外还可以做劫持防御,所谓「一石三鸟」!
# 3. 最后方式
- 使用 https
- 打官司
# 参考
- 本文链接: https://mrgaogang.github.io/javascript/deep/%E5%89%8D%E7%AB%AF%E9%A1%B5%E9%9D%A2%E5%8A%AB%E6%8C%81%E5%92%8C%E5%8F%8D%E5%8A%AB%E6%8C%81.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 许可协议。转载请注明出处!