


# JavaScript 设计模式核⼼原理与应⽤实践
# 0. 开篇:前端工程师的成长论
# # 0. 开篇:前端工程师的成长论
能够决定一个前端工程师的本质的,不是那些瞬息万变的技术点,而是那些不变的东西。
所谓“不变的东西”,说的就是这种驾驭技术的能力。
具体来说,它分为以下三个层次:
- 能用健壮的代码去解决具体的问题;
- 能用抽象的思维去应对复杂的系统;
- 能用工程化的思想去规划更大规模的业务。
这三种能力在你的成长过程中是层层递进的关系,而后两种能力可以说是对架构师的要求。事实上,在我入行以来接触过的工程师里,能做到第一点,并且把它做到扎实、做到娴熟的人,已经堪称同辈楷模。
# # 0.1 前端工程师,首先是软件工程师
很多人缺乏的并不是这种高瞻远瞩的激情,而是我们前面提到的“不变能力”中最基本的那一点——用健壮的代码去解决具体的问题的能力。
所以说,想做靠谱开发,先掌握设计模式。

# # 1. 设计模式的“道”与“术”
# # 1.1 设计模式,究竟有着怎样的力量?
每一个模式描述了一个在我们周围不断重复发生的问题,以及该问题的解决方案的核心。这样,你就能一次又一次地使用该方案而不必做重复劳动。 —— Christopher Alexander
# # 1.2 SOLID 设计原则
"SOLID" 是由罗伯特·C·马丁在 21 世纪早期引入的记忆术首字母缩略字,指代了面向对象编程和面向对象设计的五个基本原则。
设计原则是设计模式的指导理论,它可以帮助我们规避不良的软件设计。SOLID 指代的五个基本原则分别是:
- 单一功能原则(Single Responsibility Principle)
- 一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
- 开放封闭原则(Opened Closed Principle)
- 核心的思想是软件实体(类、模块、函数等)是可扩展的、但不可修改的。也就是说,对扩展是开放的,而对修改是封闭的。
- 里式替换原则(Liskov Substitution Principle)
- 接口隔离原则(Interface Segregation Principle)
- 依赖反转原则(Dependency Inversion Principle)
在 JavaScript 设计模式中,主要用到的设计模式基本都围绕“单一功能”和“开放封闭”这两个原则来展开。
# # 1.3 设计模式的核心思想——封装变化
设计模式出现的背景,是软件设计的复杂度日益飙升。软件设计越来越复杂的“罪魁祸首”,就是变化。
这一点相信大家不难理解——如果说我们写一个业务,这个业务是一潭死水,初始版本是 1.0,100 年后还是 1.0,不接受任何迭代和优化,那么这个业务几乎可以随便写。反正只要实现功能就行了,完全不需要考虑可维护性、可扩展性。
但在实际开发中,不发生变化的代码可以说是不存在的。我们能做的只有将这个变化造成的影响最小化 —— 将变与不变分离,确保变化的部分灵活、不变的部分稳定。
这个过程,就叫“封装变化”;这样的代码,就是我们所谓的“健壮”的代码,它可以经得起变化的考验。而设计模式出现的意义,就是帮我们写出这样的代码。
# # 1.4 设计模式的“术”
所谓“术”,其实就是指二十年前 GOF 提出的最经典的 23 种设计模式。二十年前,四位程序员前辈(Erich Gamma, Richard Helm, Ralph Johnson & John Vlissides)通过编写《设计模式:可复用面向对象软件的基础》这本书,阐述了设计模式领域的开创性成果。在这本书中,将 23 种设计模式按照“创建型”、“行为型”和“结构型”进行划分:

前面我们说过,设计模式的核心思想,就是“封装变化”。确实如此,无论是创建型、结构型还是行为型,这些具体的设计模式都是在用自己的方式去封装不同类型的变化 —— 创建型模式封装了创建对象过程中的变化,比如下节的工厂模式,它做的事情就是将创建对象的过程抽离;结构型模式封装的是对象之间组合方式的变化,目的在于灵活地表达对象间的配合与依赖关系;而行为型模式则将是对象千变万化的行为进行抽离,确保我们能够更安全、更方便地对行为进行更改。
封装变化,封装的正是软件中那些不稳定的要素,它是一种防患于未然的行为 —— 提前抽离了变化,就为后续的拓展提供了无限的可能性,如此,我们才能做到在变化到来的时候从容不迫。
# # 1.5 从 Java/C++ 到 JavaScript 的迁移
设计模式迁移到 JavaScript,不仅仅是从一类语言到另一类语言这么简单。强类型语言不仅和 JavaScript 之间存在着基本语法的差异,还存在着应用场景的差异。设计模式的“前端化”,正是我们后续十余个章节要做的事情。在这个过程中,场景是基础,代码是辅助,逻辑是主角。
# # 2. 创建型:工厂模式·简单工厂——区分“变与不变”
# # 2.1 先来说说构造器
在介绍工厂模式之前,为了辅助大家的理解,我想先在这儿给大家介绍一下构造器模式。
别看这个名字很吓人(其实设计模式里每个名字好像都挺吓人的哈哈哈),这玩意儿你几乎天天用(所以咱们不单独给它开小节),不信你来看看:
有一天你写了个公司员工信息录入系统,这个系统开发阶段用户只有你自己,想怎么玩怎么玩。于是在创建“自己”这个唯一的用户的时候,你可以这么写:
const liLei = {
name: "李雷",
age: 25,
career: "coder",
};
有一天你的同桌韩梅梅突然说:“李雷,让我瞅瞅你的系统做得咋样了,我也想被录进去”。你说好,不就多一个人的事情吗,于是代码里手动多了一个韩梅梅:
const liLei = {
name: "李雷",
age: 25,
career: "coder",
};
const hanMeiMei = {
name: "韩梅梅",
age: 24,
career: "product manager",
};
又过了两天你老板过来了,说李雷,系统今天提测了,先把部门的 500 人录入看看功能。李雷心想,500 个对象字面量,要死要死,还好我有构造函数。于是李雷写出了一个可以自动创建用户的 User 函数:
function User(name, age, career) {
this.name = name;
this.age = age;
this.career = career;
}
楼上个这 User,就是一个构造器。此处我们采用了 ES5 构造函数的写法,因为 ES6 中的 class 其实本质上还是函数,class 语法只是语法糖,构造函数,才是它的真面目。
接下来要做的事情,就是让程序自动地去读取数据库里面一行行的员工信息,然后把拿到的姓名、年龄等字段塞进 User 函数里,进行一个简单的调用:
const user = new User(name, age, career)
从此李雷再也不用手写字面量。
像 User 这样当新建对象的内存被分配后,用来初始化该对象的特殊函数,就叫做构造器。在 JavaScript 中,我们使用构造函数去初始化对象,就是应用了构造器模式。这个模式太简单了,简单到我这一通讲对很多同学来说其实并不必要,大家都是学过 JavaScript 基础的人,都知道怎么 new 一个对象。但是我们洋洋洒洒这么一段的目的,并不是为了带大家复习构造函数本身的用法,而是希望大家去思考开篇我们提到的问题:
在创建一个 user 过程中,谁变了,谁不变?
很明显,变的是每个 user 的姓名、年龄、工种这些值,这是用户的个性,不变的是每个员工都具备姓名、年龄、工种这些属性,这是用户的共性。
那么构造器做了什么?
构造器是不是将 name、age、career 赋值给对象的过程封装,确保了每个对象都具备这些属性,确保了共性的不变,同时将 name、age、career 各自的取值操作开放,确保了个性的灵活?
如果在使用构造器模式的时候,我们本质上是去抽象了每个对象实例的变与不变。那么使用工厂模式时,我们要做的就是去抽象不同构造函数(类)之间的变与不变
# # 2.1 简单工厂模式
咱们先不说简单工厂模式定义是啥,咱们先来看李雷的新需求:
老板说这个系统录入的信息也太简单了,程序员和产品经理之间的区别一个简单的 career 字段怎么能说得清?我要求这个系统具备给不同工种分配职责说明的功能。也就是说,要给每个工种的用户加上一个个性化的字段,来描述他们的工作内容。
完了,这下员工的共性被拆离了。还好有构造器,李雷心想不就是多写个构造器的事儿吗,我写:
function Coder(name, age) {
this.name = name;
this.age = age;
this.career = "coder";
this.work = ["写代码", "写系分", "修Bug"];
}
function ProductManager(name, age) {
this.name = name;
this.age = age;
this.career = "product manager";
this.work = ["订会议室", "写PRD", "催更"];
}
现在我们有两个类(后面可能还会有更多的类),麻烦的事情来了:难道我每从数据库拿到一条数据,都要人工判断一下这个员工的工种,然后手动给它分配构造器吗?不行,这也是一个“变”,我们把这个“变”交给一个函数去处理:
function Factory(name, age, career) {
switch(career) {
case 'coder':
return new Coder(name, age)
break
case 'product manager':
return new ProductManager(name, age)
break
...
}
看起来是好一些了,至少我们不用操心构造函数的分配问题了。但是大家注意我在 switch 的末尾写了个省略号,这个省略号比较恐怖。看着这个省略号,李雷哭了,他想到:整个公司上下有数十个工种,难道我要手写数十个类、数十行 switch 吗?
当然不!回到我们最初的问题:大家仔细想想,在楼上这两段并不那么好的代码里,变的是什么?不变的又是什么?
Coder 和 ProductManager 两个工种的员工,是不是仍然存在都拥有 name、age、career、work 这四个属性这样的共性?它们之间的区别,在于每个字段取值的不同,以及 work 字段需要随 career 字段取值的不同而改变。这样一来,我们是不是对共性封装得不够彻底?那么相应地,共性与个性是不是分离得也不够彻底?
现在我们把相同的逻辑封装回 User 类里,然后把这个承载了共性的 User 类和个性化的逻辑判断写入同一个函数:
function User(name , age, career, work) {
this.name = name
this.age = age
this.career = career
this.work = work
}
function Factory(name, age, career) {
let work
switch(career) {
case 'coder':
work = ['写代码','写系分', '修Bug']
break
case 'product manager':
work = ['订会议室', '写PRD', '催更']
break
case 'boss':
work = ['喝茶', '看报', '见客户']
case 'xxx':
// 其它工种的职责分配
...
return new User(name, age, career, work)
}
这样一来,我们要做事情是不是简单太多了?不用自己时刻想着我拿到的这组数据是什么工种、我应该怎么给它分配构造函数,更不用手写无数个构造函数——Factory 已经帮我们做完了一切,而我们只需要像以前一样无脑传参就可以了!
现在我们一起来总结一下什么是工厂模式:工厂模式其实就是将创建对象的过程单独封装。它很像我们去餐馆点菜:比如说点一份西红柿炒蛋,我们不用关心西红柿怎么切、怎么打鸡蛋这些菜品制作过程中的问题,我们只关心摆上桌那道菜。在工厂模式里,我传参这个过程就是点菜,工厂函数里面运转的逻辑就相当于炒菜的厨师和上桌的服务员做掉的那部分工作——这部分工作我们同样不用关心,我们只要能拿到工厂交付给我们的实例结果就行了。
# # 2.3 小结
工厂模式的简单之处,在于它的概念相对好理解:将创建对象的过程单独封装,这样的操作就是工厂模式。同时它的应用场景也非常容易识别:有构造函数的地方,我们就应该想到简单工厂;在写了大量构造函数、调用了大量的 new、自觉非常不爽的情况下,我们就应该思考是不是可以掏出工厂模式重构我们的代码了。
# # 3. 创建型:工厂模式·抽象工厂——理解“开放封闭”
# # 3.1 一个不简单的简单工厂引发的命案
在实际的业务中,我们往往面对的复杂度并非数个类、一个工厂可以解决,而是需要动用多个工厂。
我们继续看上个小节举出的例子,简单工厂函数最后长这样:
function Factory(name, age, career) {
let work
switch(career) {
case 'coder':
work = ['写代码','写系分', '修Bug']
break
case 'product manager':
work = ['订会议室', '写PRD', '催更']
break
case 'boss':
work = ['喝茶', '看报', '见客户']
case 'xxx':
// 其它工种的职责分配
...
return new User(name, age, career, work)
}
乍一看没什么问题,但是经不起推敲呀。首先映入眼帘的 Bug,是我们把 Boss 这个角色和普通员工塞进了一个工厂。大家知道,Boss 和基层员工在职能上差别还是挺大的,具体在员工系统里怎么表现呢?首先他的权限就跟咱们不一样。有一些系统,比如员工绩效评估的打分入口,就只有 Boss 点得进去,对不对?除此之外还有许多操作,是只有管理层可以执行的,因此我们需要对这个群体的对象进行单独的逻辑处理。
怎么办?去修改 Factory 的函数体、增加管理层相关的判断和处理逻辑吗?单从功能实现上来说,没问题。但这么做其实是在挖坑——因为公司不仅仅只有这两类人,除此之外还有外包同学、还有保安,他们的权限、职能都存在着质的差别。如果延续这个思路,每考虑到一个新的员工群体,就回去修改一次 Factory 的函数体,这样做糟糕透了——首先,是Factory 会变得异常庞大庞大到你每次添加的时候都不敢下手,生怕自己万一写出一个 Bug,就会导致整个 Factory 的崩坏,进而摧毁整个系统;其次,你坑死了你的队友:Factory 的逻辑过于繁杂和混乱,没人敢维护它;最后,你还连带坑了隔壁的测试同学:你每次新加一个工种,他都不得不对整个 Factory 的逻辑进行回归——谁让你的改变是在 Factory 内部原地发生的呢!这一切悲剧的根源只有一个——没有遵守开放封闭原则。
我们再复习一下开放封闭原则的内容:对拓展开放,对修改封闭。说得更准确点,软件实体(类、模块、函数)可以扩展,但是不可修改。楼上这波操作错就错在我们不是在拓展,而是在疯狂地修改。
# # 3.2 抽象工厂模式
上面这段可能仍有部分同学觉得抽象,也没关系。这里咱们先不急着理解透彻这个干巴巴的概念,先来看这么一个示例:
大家知道一部智能手机的基本组成是操作系统(Operating System,我们下面缩写作 OS)和硬件(HardWare)组成。所以说如果我要开一个山寨手机工厂,那我这个工厂里必须是既准备好了操作系统,也准备好了硬件,才能实现手机的量产。考虑到操作系统和硬件这两样东西背后也存在不同的厂商,而我现在并不知道我下一个生产线到底具体想生产一台什么样的手机,我只知道手机必须有这两部分组成,所以我先来一个抽象类来约定住这台手机的基本组成:
class MobilePhoneFactory {
// 提供操作系统的接口
createOS() {
throw new Error("抽象工厂方法不允许直接调用,你需要将我重写!");
}
// 提供硬件的接口
createHardWare() {
throw new Error("抽象工厂方法不允许直接调用,你需要将我重写!");
}
}
楼上这个类,除了约定手机流水线的通用能力之外,啥也不干。如果你尝试让它干点啥,比如 new 一个 MobilePhoneFactory 实例,并尝试调用它的实例方法。它还会给你报错,提醒你“我不是让你拿去 new 一个实例的,我就是个定规矩的”。在抽象工厂模式里,楼上这个类就是我们食物链顶端最大的 Boss——AbstractFactory(抽象工厂)。
抽象工厂不干活,具体工厂(ConcreteFactory)来干活!当我们明确了生产方案,明确某一条手机生产流水线具体要生产什么样的手机了之后,就可以化抽象为具体,比如我现在想要一个专门生产 Android 系统 + 高通硬件的手机的生产线,我给这类手机型号起名叫 FakeStar,那我就可以为 FakeStar 定制一个具体工厂:
// 具体工厂继承自抽象工厂
class FakeStarFactory extends MobilePhoneFactory {
createOS() {
// 提供安卓系统实例
return new AndroidOS();
}
createHardWare() {
// 提供高通硬件实例
return new QualcommHardWare();
}
}
这里我们在提供安卓系统的时候,调用了两个构造函数:AndroidOS 和 QualcommHardWare,它们分别用于生成具体的操作系统和硬件实例。像这种被我们拿来用于 new 出具体对象的类,叫做具体产品类(ConcreteProduct)。具体产品类往往不会孤立存在,不同的具体产品类往往有着共同的功能,比如安卓系统类和苹果系统类,它们都是操作系统,都有着可以操控手机硬件系统这样一个最基本的功能。因此我们可以用一个抽象产品(AbstractProduct)类来声明这一类产品应该具有的基本功能(众:什么抽象产品???要这些玩意儿干啥?老夫写代码就是一把梭,为啥不让我老老实实一个一个写具体类???大家稍安勿躁,先把例子看完,下文会有解释)
// 定义操作系统这类产品的抽象产品类
class OS {
controlHardWare() {
throw new Error('抽象产品方法不允许直接调用,你需要将我重写!');
}
}
// 定义具体操作系统的具体产品类
class AndroidOS extends OS {
controlHardWare() {
console.log('我会用安卓的方式去操作硬件')
}
}
class AppleOS extends OS {
controlHardWare() {
console.log('我会用🍎的方式去操作硬件')
}
}
...
硬件类产品同理:
// 定义手机硬件这类产品的抽象产品类
class HardWare {
// 手机硬件的共性方法,这里提取了“根据命令运转”这个共性
operateByOrder() {
throw new Error('抽象产品方法不允许直接调用,你需要将我重写!');
}
}
// 定义具体硬件的具体产品类
class QualcommHardWare extends HardWare {
operateByOrder() {
console.log('我会用高通的方式去运转')
}
}
class MiWare extends HardWare {
operateByOrder() {
console.log('我会用小米的方式去运转')
}
}
...
好了,如此一来,当我们需要生产一台 FakeStar 手机时,我们只需要这样做:
// 这是我的手机
const myPhone = new FakeStarFactory();
// 让它拥有操作系统
const myOS = myPhone.createOS();
// 让它拥有硬件
const myHardWare = myPhone.createHardWare();
// 启动操作系统(输出‘我会用安卓的方式去操作硬件’)
myOS.controlHardWare();
// 唤醒硬件(输出‘我会用高通的方式去运转’)
myHardWare.operateByOrder();
关键的时刻来了——假如有一天,FakeStar 过气了,我们需要产出一款新机投入市场,这时候怎么办?我们是不是不需要对抽象工厂 MobilePhoneFactory 做任何修改,只需要拓展它的种类:
class newStarFactory extends MobilePhoneFactory {
createOS() {
// 操作系统实现代码
}
createHardWare() {
// 硬件实现代码
}
}
这么个操作,对原有的系统不会造成任何潜在影响所谓的“对拓展开放,对修改封闭”就这么圆满实现了。前面我们之所以要实现抽象产品类,也是同样的道理。
# # 3.3 总结
大家现在回头对比一下抽象工厂和简单工厂的思路,思考一下:它们之间有哪些异同?
它们的共同点,在于都尝试去分离一个系统中变与不变的部分。它们的不同在于场景的复杂度。在简单工厂的使用场景里,处理的对象是类,并且是一些非常好对付的类——它们的共性容易抽离,同时因为逻辑本身比较简单,故而不苛求代码可扩展性。抽象工厂本质上处理的其实也是类,但是是一帮非常棘手、繁杂的类,这些类中不仅能划分出门派,还能划分出等级,同时存在着千变万化的扩展可能性——这使得我们必须对共性作更特别的处理、使用抽象类去降低扩展的成本,同时需要对类的性质作划分,于是有了这样的四个关键角色:
- 抽象工厂(抽象类,它不能被用于生成具体实例):用于声明最终目标产品的共性。在一个系统里,抽象工厂可以有多个(大家可以想象我们的手机厂后来被一个更大的厂收购了,这个厂里除了手机抽象类,还有平板、游戏机抽象类等等),每一个抽象工厂对应的这一类的产品,被称为“产品族”。
- 具体工厂(用于生成产品族里的一个具体的产品): 继承自抽象工厂、实现了抽象工厂里声明的那些方法,用于创建具体的产品的类。
- 抽象产品(抽象类,它不能被用于生成具体实例) :上面我们看到,具体工厂里实现的接口,会依赖一些类,这些类对应到各种各样的具体的细粒度产品(比如操作系统、硬件等),这些具体产品类的共性各自抽离,便对应到了各自的抽象产品类。
- 具体产品(用于生成产品族里的一个具体的产品所依赖的更细粒度的产品) :比如我们上文中具体的一种操作系统、或具体的一种硬件等。
抽象工厂模式的定义,是围绕一个超级工厂创建其他工厂。抽象工厂目前来说在 JS 世界里也应用得并不广泛,所以大家不必拘泥于细节,只需留意以下三点:
- 学会用 ES6 模拟 JAVA 中的抽象类;
- 了解抽象工厂模式中四个角色的定位与作用;
- 对“开放封闭原则”形成自己的理解,知道它好在哪,知道执行它的必要性。
# # 4. 创建型:单例模式——Vuex 的数据管理哲学
保证一个类仅有一个实例,并提供一个访问它的全局访问点,这样的模式就叫做单例模式。
# # 4.1 单例模式的实现思路
思考这样一个问题:如何才能保证一个类仅有一个实例?
一般情况下,当我们创建了一个类(本质是构造函数)后,可以通过 new 关键字调用构造函数进而生成任意多的实例对象。像这样:
class SingleDog {
show() {
console.log('我是一个单例对象')
}
}
const s1 = new SingleDog()
const s2 = new SingleDog()
// false
s1 === s2
楼上我们先 new 了一个 s1,又 new 了一个 s2,很明显 s1 和 s2 之间没有任何瓜葛,两者是相互独立的对象,各占一块内存空间。而单例模式想要做到的是,不管我们尝试去创建多少次,它都只给你返回第一次所创建的那唯一的一个实例。
要做到这一点,就需要构造函数具备判断自己是否已经创建过一个实例的能力。我们现在把这段判断逻辑写成一个静态方法(其实也可以直接写入构造函数的函数体里):
class SingleDog {
show() {
console.log('我是一个单例对象')
}
static getInstance() {
// 判断是否已经new过1个实例
if (!SingleDog.instance) {
// 若这个唯一的实例不存在,那么先创建它
SingleDog.instance = new SingleDog()
}
// 如果这个唯一的实例已经存在,则直接返回
return SingleDog.instance
}
}
const s1 = SingleDog.getInstance()
const s2 = SingleDog.getInstance()
// true
s1 === s2
除了楼上这种实现方式之外,getInstance 的逻辑还可以用闭包来实现:
SingleDog.getInstance = (function() {
// 定义自由变量instance,模拟私有变量
let instance = null
return function() {
// 判断自由变量是否为null
if(!instance) {
// 如果为null则new出唯一实例
instance = new SingleDog()
}
return instance
}
})()
可以看出,在 getInstance 方法的判断和拦截下,我们不管调用多少次,SingleDog 都只会给我们返回一个实例,s1 和 s2 现在都指向这个唯一的实例。
# # 4.2 生产实践:Vuex 中的单例模式
# # 4.2.1 理解 Vuex 中的 Store
Vuex 使用单一状态树,用一个对象就包含了全部的应用层级状态。至此它便作为一个“唯一数据源 (SSOT)”而存在。这也意味着,每个应用将仅仅包含一个 store 实例。单一状态树让我们能够直接地定位任一特定的状态片段,在调试的过程中也能轻易地取得整个当前应用状态的快照。 ——Vuex 官方文档
在 Vue 中,组件之间是独立的,组件间通信最常用的办法是 props(限于父组件和子组件之间的通信),稍微复杂一点的(比如兄弟组件间的通信)我们通过自己实现简单的事件监听函数也能解决掉。
但当组件非常多、组件间关系复杂、且嵌套层级很深的时候,这种原始的通信方式会使我们的逻辑变得复杂难以维护。这时最好的做法是将共享的数据抽出来、放在全局,供组件们按照一定的的规则去存取数据,保证状态以一种可预测的方式发生变化。于是便有了 Vuex,这个用来存放共享数据的唯一数据源,就是 Store。
# # 4.2.2 Vuex 如何确保 Store 的唯一性
// 安装vuex插件
Vue.use(Vuex)
// 将store注入到Vue实例中
new Vue({
el: '#app',
store
})
通过调用 Vue.use()方法,我们安装了 Vuex 插件。Vuex 插件是一个对象,它在内部实现了一个 install 方法,这个方法会在插件安装时被调用,从而把 Store 注入到 Vue 实例里去。也就是说每 install 一次,都会尝试给 Vue 实例注入一个 Store。
在 install 方法里,有一段逻辑和我们楼上的 getInstance 非常相似的逻辑:
let Vue // 这个Vue的作用和楼上的instance作用一样
...
export function install (_Vue) {
// 判断传入的Vue实例对象是否已经被install过Vuex插件(是否有了唯一的state)
if (Vue && _Vue === Vue) {
if (process.env.NODE_ENV !== 'production') {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
}
return
}
// 若没有,则为这个Vue实例对象install一个唯一的Vuex
Vue = _Vue
// 将Vuex的初始化逻辑写进Vue的钩子函数里
applyMixin(Vue)
}
楼上便是 Vuex 源码中单例模式的实现办法了,套路可以说和我们的 getInstance 如出一辙。通过这种方式,可以保证一个 Vue 实例(即一个 Vue 应用)只会被 install 一次 Vuex 插件,所以每个 Vue 实例只会拥有一个全局的 Store。
# # 4.3 小结
思考一下:如果我在 install 里没有实现单例模式,会带来什么样的麻烦?
我们通过上面的源码解析可以看出,每次 install 都会为 Vue 实例初始化一个 Store。假如 install 里没有单例模式的逻辑,那我们如果在一个应用里不小心多次安装了插件:
// 在主文件里安装Vuex
Vue.use(Vuex)
...(中间添加/修改了一些store的数据)
// 在后续的逻辑里不小心又安装了一次
Vue.use(Vuex)
失去了单例判断能力的 install 方法,会为当前的 Vue 实例重新注入一个新的 Store,也就是说你中间的那些数据操作全都没了,一切归 0。因此,单例模式在此处是非常必要的。
# # 5. 创建型:单例模式——面试真题手把手教学
# # 5.1 实现一个 Storage
描述
实现 Storage,使得该对象为单例,基于 localStorage 进行封装。实现方法 setItem(key,value) 和 getItem(key)。
思路
拿到单例模式相关的面试题,大家首先要做的是回忆我们上个小节的“基本思路”部分——至少要记起来getInstance方法和instance这个变量是干啥的。
具体实现上,把判断逻辑写入静态方法或者构造函数里都没关系,最好能把闭包的版本也写出来,多多益善。
总之有了上节的基础,这个题简直是默写!
实现:静态方法版
// 定义Storage
class Storage {
static getInstance() {
// 判断是否已经new过1个实例
if (!Storage.instance) {
// 若这个唯一的实例不存在,那么先创建它
Storage.instance = new Storage()
}
// 如果这个唯一的实例已经存在,则直接返回
return Storage.instance
}
getItem (key) {
return localStorage.getItem(key)
}
setItem (key, value) {
return localStorage.setItem(key, value)
}
}
const storage1 = Storage.getInstance()
const storage2 = Storage.getInstance()
storage1.setItem('name', '李雷')
// 李雷
storage1.getItem('name')
// 也是李雷
storage2.getItem('name')
// 返回true
storage1 === storage2
实现: 闭包版
// 先实现一个基础的StorageBase类,把getItem和setItem方法放在它的原型链上
function StorageBase () {}
StorageBase.prototype.getItem = function (key){
return localStorage.getItem(key)
}
StorageBase.prototype.setItem = function (key, value) {
return localStorage.setItem(key, value)
}
// 以闭包的形式创建一个引用自由变量的构造函数
const Storage = (function(){
let instance = null
return function(){
// 判断自由变量是否为null
if(!instance) {
// 如果为null则new出唯一实例
instance = new StorageBase()
}
return instance
}
})()
// 这里其实不用 new Storage 的形式调用,直接 Storage() 也会有一样的效果
const storage1 = new Storage()
const storage2 = new Storage()
storage1.setItem('name', '李雷')
// 李雷
storage1.getItem('name')
// 也是李雷
storage2.getItem('name')
// 返回true
storage1 === storage2
# # 5.2 实现一个全局的模态框
描述
实现一个全局唯一的 Modal 弹框
思路
这道题比较经典,基本上所有讲单例模式的文章都会以此为例,同时它也是早期单例模式在前端领域的最集中体现。
万变不离其踪,记住 getInstance 方法、记住 instance 变量、记住闭包和静态方法,这个题除了要多写点 HTML 和 CSS 之外,对大家来说完全不成问题。
实现
完整代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>单例模式弹框</title>
</head>
<style>
#modal {
height: 200px;
width: 200px;
line-height: 200px;
position: fixed;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
border: 1px solid black;
text-align: center;
}
</style>
<body>
<button id='open'>打开弹框</button>
<button id='close'>关闭弹框</button>
</body>
<script>
// 核心逻辑,这里采用了闭包思路来实现单例模式
const Modal = (function() {
let modal = null
return function() {
if(!modal) {
modal = document.createElement('div')
modal.innerHTML = '我是一个全局唯一的Modal'
modal.id = 'modal'
modal.style.display = 'none'
document.body.appendChild(modal)
}
return modal
}
})()
// 点击打开按钮展示模态框
document.getElementById('open').addEventListener('click', function() {
// 未点击则不创建modal实例,避免不必要的内存占用;此处不用 new Modal 的形式调用也可以,和 Storage 同理
const modal = new Modal()
modal.style.display = 'block'
})
// 点击关闭按钮隐藏模态框
document.getElementById('close').addEventListener('click', function() {
const modal = new Modal()
if(modal) {
modal.style.display = 'none'
}
})
</script>
</html>
是不是发现又是熟悉的套路?又可以默写了?(ES6 版本的实现大家自己尝试默写一下,相信对现在的你来说已经非常简单了)。
这就是单例模式面试题的特点,准确地说,是所有设计模式相关面试题的特点——牢记核心思路,就能举一反三。所以说设计模式的学习是典型的一分耕耘一分收获,性价比极高。
# # 6. 创建型:原型模式——谈 Prototype 无小事
原型模式不仅是一种设计模式,它还是一种编程范式(programming paradigm),是 JavaScript 面向对象系统实现的根基。
在原型模式下,当我们想要创建一个对象时,会先找到一个对象作为原型,然后通过克隆原型的方式来创建出一个与原型一样(共享一套数据/方法)的对象。在 JavaScript 里,Object.create方法就是原型模式的天然实现——准确地说,只要我们还在借助Prototype来实现对象的创建和原型的继承,那么我们就是在应用原型模式。
有的设计模式资料中会强调,原型模式就是拷贝出一个新对象,认为在 JavaScript 类里实现了深拷贝方法才算是应用了原型模式。这是非常典型的对 JAVA/C++ 设计模式的生搬硬套,更是对 JavaScript 原型模式的一种误解。事实上,在 JAVA 中,确实存在原型模式相关的克隆接口规范。但在 JavaScript 中,我们使用原型模式,并不是为了得到一个副本,而是为了得到与构造函数(类)相对应的类型的实例、实现数据/方法的共享。克隆是实现这个目的的方法,但克隆本身并不是我们的目的。
# # 6.1 以类为中心的语言和以原型为中心的语言
相信很多小伙伴读到这儿还会有些迷惑:使用 JavaScript 以来,我确实离不开 Prototype,按照上面的说法,也算是原型模式重度用户了。但这个原型模式用得我一脸懵逼啊——难道我还有除了 Prototype 以外的选择?
# # 6.1.1 Java 中的类
作为 JavaScript 开发者,我们确实没有别的选择 —— 毕竟开头我们说过,原型模式是 JavaScript 这门语言面向对象系统的根本。但在其它语言,比如 JAVA 中,类才是它面向对象系统的根本。所以说在 JAVA 中,我们可以选择不使用原型模式 —— 这样一来,所有的实例都必须要从类中来,当我们希望创建两个一模一样的实例时,就只能这样做(假设实例从 Dog 类中来,必传参数为姓名、性别、年龄和品种):
Dog dog = new Dog('旺财', 'male', 3, '柴犬')
Dog dog_copy = new Dog('旺财', 'male', 3, '柴犬')
没错,我们不得不把一模一样的参数传两遍,非常麻烦。而原型模式允许我们通过调用克隆方法的方式达到同样的目的,比较方便,所以 Java 专门针对原型模式设计了一套接口和方法,在必要的场景下会通过原型方法来应用原型模式。当然,在更多的情况下,Java 仍以“实例化类”这种方式来创建对象。
# # 6.1.2 JavaScript 中的“类”
这时有一部分小伙伴估计要炸毛了:啥???JavaScript 只能用 Prototype?我看你还活在上世纪,ES6 早就支持类了!现在我们 JavaScript 也是以类为中心的语言了。
这波同学的思想非常危险,因为 ES6 的类其实是原型继承的语法糖:
ECMAScript 2015 中引入的 JavaScript 类实质上是 JavaScript 现有的基于原型的继承的语法糖。类语法不会为 JavaScript 引入新的面向对象的继承模型。 ——MDN
当我们尝试用 class 去定义一个 Dog 类时:
class Dog {
constructor(name ,age) {
this.name = name
this.age = age
}
eat() {
console.log('肉骨头真好吃')
}
}
其实完全等价于写了这么一个构造函数:
function Dog(name, age) {
this.name = name
this.age = age
}
Dog.prototype.eat = function() {
console.log('肉骨头真好吃')
}
所以说 JavaScript 这门语言的根本就是原型模式。在 Java 等强类型语言中,原型模式的出现是为了实现类型之间的解耦。而 JavaScript 本身类型就比较模糊,不存在类型耦合的问题,所以说咱们平时根本不会刻意地去使用原型模式。因此我们此处不必强行把原型模式当作一种设计模式去理解,把它作为一种编程范式来讨论会更合适。
# # 6.2 谈原型模式,其实是谈原型范式
原型编程范式的核心思想就是利用实例来描述对象,用实例作为定义对象和继承的基础。在 JavaScript 中,原型编程范式的体现就是基于原型链的继承。这其中,对原型、原型链的理解是关键。
# # 6.2.1 原型
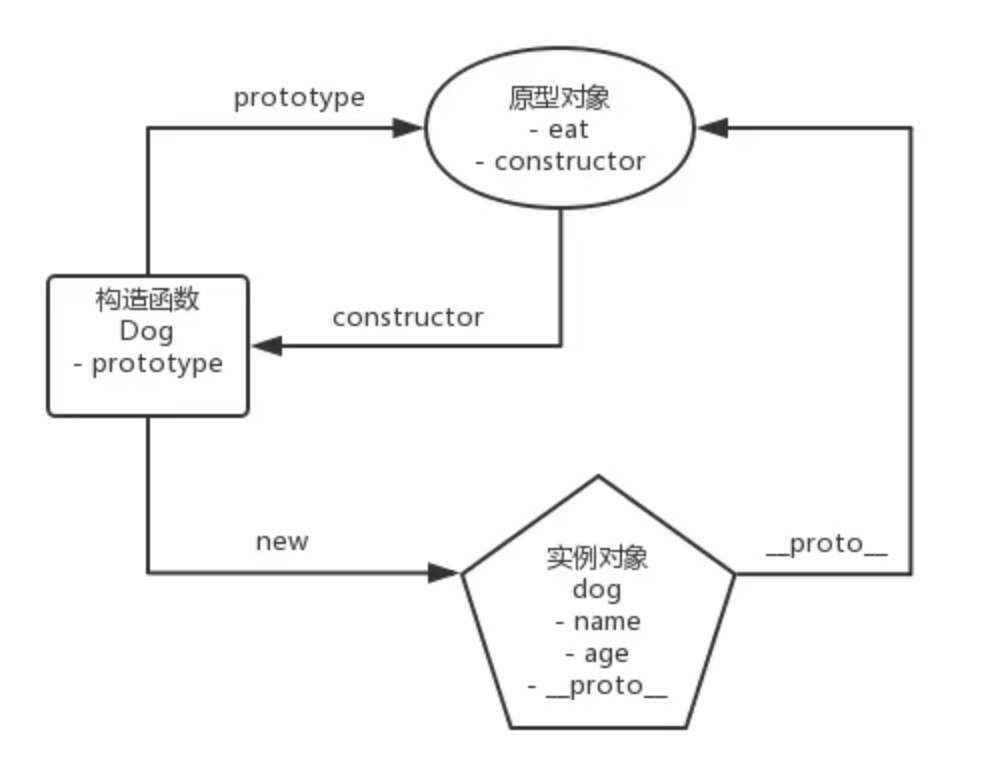
在 JavaScript 中,每个构造函数都拥有一个prototype属性,它指向构造函数的原型对象,这个原型对象中有一个 construtor 属性指回构造函数;每个实例都有一个__proto__属性,当我们使用构造函数去创建实例时,实例的__proto__属性就会指向构造函数的原型对象。
具体来说,当我们这样使用构造函数创建一个对象时:
// 创建一个Dog构造函数
function Dog(name, age) {
this.name = name
this.age = age
}
Dog.prototype.eat = function() {
console.log('肉骨头真好吃')
}
// 使用Dog构造函数创建dog实例
const dog = new Dog('旺财', 3)
这段代码里的几个实体之间就存在着这样的关系:
# # 6.2.1 原型链
现在我在上面那段代码的基础上,进行两个方法调用:
// 输出"肉骨头真好吃"
dog.eat()
// 输出"[object Object]"
dog.toString()
明明没有在 dog 实例里手动定义 eat 方法和 toString 方法,它们还是被成功地调用了。这是因为当我试图访问一个 JavaScript 实例的属性/方法时,它首先搜索这个实例本身;当发现实例没有定义对应的属性/方法时,它会转而去搜索实例的原型对象;如果原型对象中也搜索不到,它就去搜索原型对象的原型对象,这个搜索的轨迹,就叫做原型链。
以我们的 eat 方法和 toString 方法的调用过程为例,它的搜索过程就是这样子的:
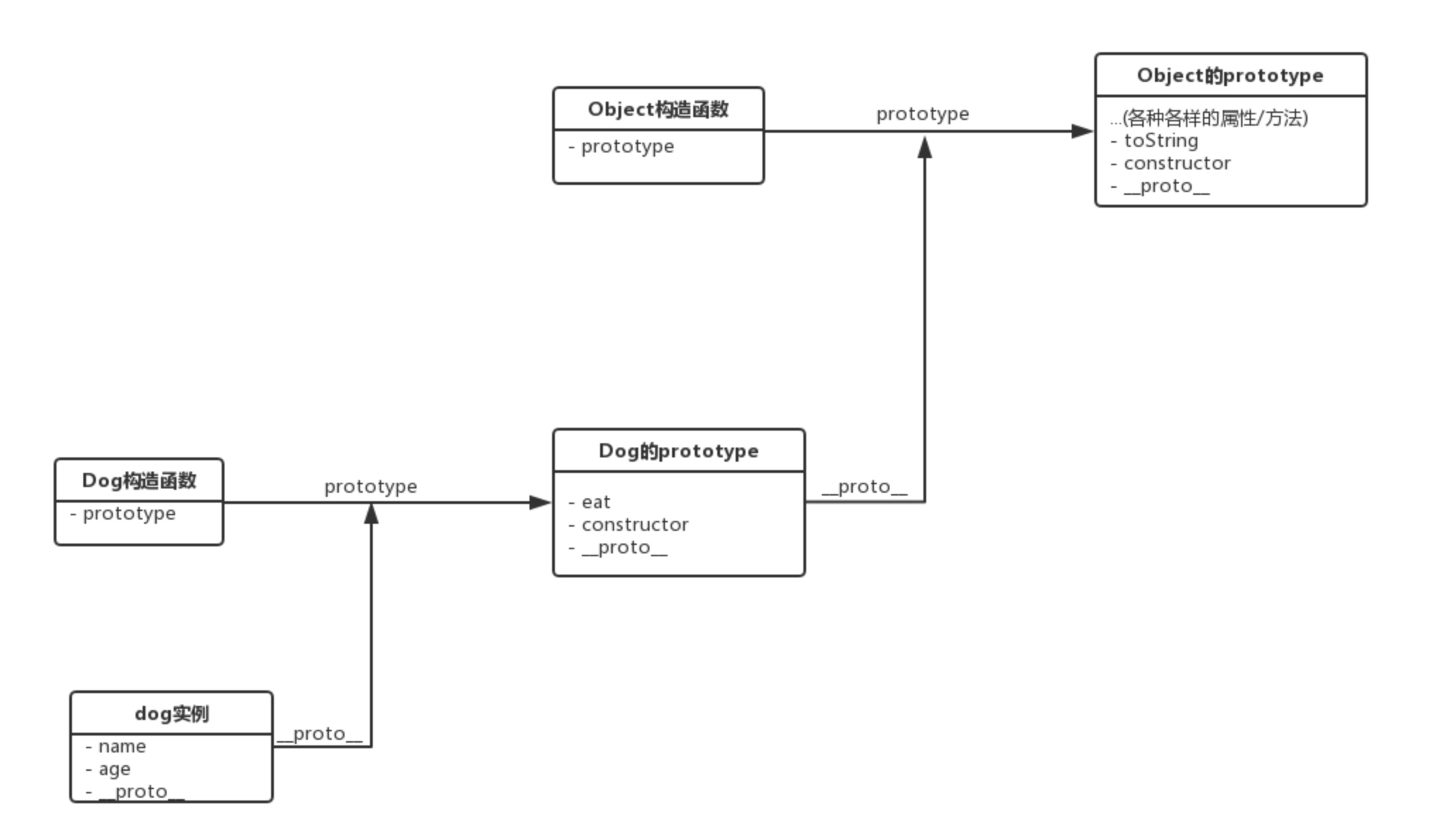
楼上这些彼此相连的 prototype,就组成了一个原型链。 注: 几乎所有 JavaScript 中的对象都是位于原型链顶端的 Object 的实例,除了Object.prototype(当然,如果我们手动用Object.create(null)创建一个没有任何原型的对象,那它也不是 Object 的实例)。
以上为大家介绍了原型、原型链等 JavaScript 中核心的基础知识。这些不仅是基础中的基础,也是面试中的重点。此外在面试中,一些面试官可能会刻意混淆 JavaScript 中原型范式和强类型语言中原型模式的区别,当他们这么做的时候不一定是因为对语言、对设计模式的理解有问题,而很有可能是为了考察你对象的深拷贝。
# # 6.3 对象的深拷贝
这类题目的发问方式又很多,除了“模拟 JAVA 中的克隆接口”、“JavaScript 实现原型模式”以外,它更常见、更友好的发问形式是“请实现 JS 中的深拷贝”。
实现 JavaScript 中的深拷贝,有一种非常取巧的方式 —— JSON.stringify:
const liLei = {
name: 'lilei',
age: 28,
habits: ['coding', 'hiking', 'running']
}
const liLeiStr = JSON.stringify(liLei)
const liLeiCopy = JSON.parse(liLeiStr)
liLeiCopy.habits.splice(0, 1)
console.log('李雷副本的habits数组是', liLeiCopy.habits)
console.log('李雷的habits数组是', liLei.habits)
丢进控制台检验一下,我们发现引用类型也被成功拷贝了,副本和本体相互不干扰,正合我意~

但是注意,这个方法存在一些局限性,比如无法处理 function、无法处理正则等等——只有当你的对象是一个严格的 JSON 对象时,可以顺利使用这个方法。在面试过程中,大家答出这个答案没有任何问题,但不要仅仅答这一种做法。
深拷贝没有完美方案,每一种方案都有它的边界 case 而面试官向你发问也并非是要求你破解人类未解之谜,多数情况下,他只是希望考查你对递归的熟练程度。所以递归实现深拷贝的核心思路,大家需要重点掌握(解析在注释里):
function deepClone(obj) {
// 如果是 值类型 或 null,则直接return
if(typeof obj !== 'object' || obj === null) {
return obj
}
// 定义结果对象
let copy = {}
// 如果对象是数组,则定义结果数组
if(obj.constructor === Array) {
copy = []
}
// 遍历对象的key
for(let key in obj) {
// 如果key是对象的自有属性
if(obj.hasOwnProperty(key)) {
// 递归调用深拷贝方法
copy[key] = deepClone(obj[key])
}
}
return copy
}
调用深拷贝方法,若属性为值类型,则直接返回;若属性为引用类型,则递归遍历。这就是我们在解这一类题时的核心的方法。
拓展阅读
深拷贝在命题时,可发挥的空间主要在于针对不同数据结构的处理,比如除了考虑 Array、Object,还需要考虑一些其它的数据结构(Map、Set 等);此外还有一些极端 case(循环引用等)的处理等等。深拷贝的实现细节,这里为大家推荐两个阅读材料:
# # 7. 结构型:装饰器模式——对象装上它,就像开了挂
装饰器模式,又名装饰者模式。它的定义是“在不改变原对象的基础上,通过对其进行包装拓展,使原有对象可以满足用户的更复杂需求”。
当然,对于没接触过装饰器的同学来说,这段定义意义不大。我们先借助一个生活中的例子来理解装饰器:
# # 7.1 生活中的装饰器
去年有个手机壳在同事里非常流行,我也随大流买了一个,它长这样:

这个手机壳的安装方式和普通手机壳一样,就是卡在手机背面。不同的是它卡上去后会变成一块水墨屏,这样一来我们手机就有了两个屏幕。平时办公或者玩游戏的时候,用正面的普通屏幕;阅读的时候怕伤眼睛,就可以翻过来用背面的水墨屏了。
这个水墨屏手机壳安装后,不会对手机原有的功能产生任何影响,仅仅是使手机具备了一种新的能力(多了块屏幕),因此它在此处就是一个标准的装饰器。
# # 7.1.2 装饰器的应用场景
按钮是我们平时写业务时常见的页面元素。假设我们的初始需求是:每个业务中的按钮在点击后都弹出「您还未登录哦」的弹框。
那我们可以很轻易地写出这个需求的代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>按钮点击需求1.0</title>
</head>
<style>
#modal {
height: 200px;
width: 200px;
line-height: 200px;
position: fixed;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
border: 1px solid black;
text-align: center;
}
</style>
<body>
<button id='open'>点击打开</button>
<button id='close'>关闭弹框</button>
</body>
<script>
// 弹框创建逻辑,这里我们复用了单例模式面试题的例子
const Modal = (function() {
let modal = null
return function() {
if(!modal) {
modal = document.createElement('div')
modal.innerHTML = '您还未登录哦~'
modal.id = 'modal'
modal.style.display = 'none'
document.body.appendChild(modal)
}
return modal
}
})()
// 点击打开按钮展示模态框
document.getElementById('open').addEventListener('click', function() {
// 未点击则不创建modal实例,避免不必要的内存占用
const modal = new Modal()
modal.style.display = 'block'
})
// 点击关闭按钮隐藏模态框
document.getElementById('close').addEventListener('click', function() {
const modal = document.getElementById('modal')
if(modal) {
modal.style.display = 'none'
}
})
</script>
</html>
按钮发布上线后,过了几天太平日子。忽然有一天,产品经理找到你,说这个弹框提示还不够明显,我们应该在弹框被关闭后把按钮的文案改为“快去登录”,同时把按钮置灰。
听到这个消息,你立刻马不停蹄地翻出之前的代码,找到了按钮的 click 监听函数,手动往里面添加了文案修改&按钮置灰逻辑。但这还没完,因为你司的几乎每个业务里都用到了这类按钮:除了“点击打开”按钮,还有“点我开始”、“点击购买”按钮等各种五花八门的按钮,这意味着你不得不深入到每一个业务的深处去给不同的按钮添加这部分逻辑。
有的业务不在你这儿,但作为这个新功能迭代的 owner,你还需要把需求细节再通知到每一个相关同事(要么你就自己上,去改别人的代码,更恐怖),怎么想怎么麻烦。一个文案修改&按钮置灰尚且如此麻烦,更不要说我们日常开发中遇到的更复杂的需求变更了
不仅麻烦,直接去修改已有的函数体,这种做法违背了我们的“开放封闭原则”;往一个函数体里塞这么多逻辑,违背了我们的“单一职责原则”。所以说这个事儿,越想越不能这么干。
我想一定会有同学质疑说为啥不把按钮抽成公共组件 Button,这样只需要在 Button 组件里修改一次逻辑就可以了。这种想法非常好。但注意,我们楼上的例子没有写组件直接写了 Button 标签是为了简化示例。事实上真要写组件的话,不同业务里必定有针对业务定制的不同 Button 组件,比如 MoreButton 、BeginButton 等等,也是五花八门的,所以说我们仍会遇到同样的困境。
讲真,我想任何人去做这个需求的时候,其实都压根不想去关心它现有的业务逻辑是啥样的——你说这按钮的旧逻辑是我自己写的还好,理解成本不高;万一碰上是个离职同事写的,那阅读难度谁能预料呢?我不想接锅,我只是想对它已有的功能做个拓展,只关心拓展出来的那部分新功能如何实现,对不对?
程序员说:“我不想努力了,我想开挂”,于是便有了装饰器模式。
# # 7.2 装饰器模式初相见
为了不被已有的业务逻辑干扰,当务之急就是将旧逻辑与新逻辑分离,把旧逻辑抽出去:
// 将展示Modal的逻辑单独封装
function openModal() {
const modal = new Modal()
modal.style.display = 'block'
}
编写新逻辑:
// 按钮文案修改逻辑
function changeButtonText() {
const btn = document.getElementById('open')
btn.innerText = '快去登录'
}
// 按钮置灰逻辑
function disableButton() {
const btn = document.getElementById('open')
btn.setAttribute("disabled", true)
}
// 新版本功能逻辑整合
function changeButtonStatus() {
changeButtonText()
disableButton()
}
然后把三个操作逐个添加 open 按钮的监听函数里:
document.getElementById('open').addEventListener('click', function() {
openModal()
changeButtonStatus()
})
如此一来,我们就实现了“只添加,不修改”的装饰器模式,使用 changeButtonStatus 的逻辑装饰了旧的按钮点击逻辑。以上是 ES5 中的实现,ES6 中,我们可以以一种更加面向对象化的方式去写:
// 定义打开按钮
class OpenButton {
// 点击后展示弹框(旧逻辑)
onClick() {
const modal = new Modal()
modal.style.display = 'block'
}
}
// 定义按钮对应的装饰器
class Decorator {
// 将按钮实例传入
constructor(open_button) {
this.open_button = open_button
}
onClick() {
this.open_button.onClick()
// “包装”了一层新逻辑
this.changeButtonStatus()
}
changeButtonStatus() {
this.changeButtonText()
this.disableButton()
}
disableButton() {
const btn = document.getElementById('open')
btn.setAttribute("disabled", true)
}
changeButtonText() {
const btn = document.getElementById('open')
btn.innerText = '快去登录'
}
}
const openButton = new OpenButton()
const decorator = new Decorator(openButton)
document.getElementById('open').addEventListener('click', function() {
// openButton.onClick()
// 此处可以分别尝试两个实例的onClick方法,验证装饰器是否生效
decorator.onClick()
})
大家这里需要特别关注一下 ES6 这个版本的实现,这里我们把按钮实例传给了 Decorator,以便于后续 Decorator 可以对它进行逻辑的拓展。在 ES7 中,Decorator 作为一种语法被直接支持了,它的书写会变得更加简单,但背后的原理其实与此大同小异。在下一节,我们将一起去探究一下 ES7 中 Decorator 背后的故事。
# # 7.3 值得关注的细节
# # 7.3.1 单一职责原则
大家可能刚刚没来得及注意,按钮新逻辑中,文本修改&按钮置灰这两个变化,被我封装在了两个不同的方法里,并以组合的形式出现在了最终的目标方法 changeButtonStatus 里。这样做的目的是为了强化大家脑中的“单一职责”意识。将不同的职责分离,可以做到每个职责都能被灵活地复用;同时,不同职责之间无法相互干扰,不会出现因为修改了 A 逻辑而影响了 B 逻辑的狗血剧情。
但是,设计原则并非是板上钉钉的教条。在此处,我们的代码总共只有两行、且比较简单,逻辑分离的诉求并不特别强,分开最好,不分影响也不大(此处我们选择了拆散两段逻辑,更多地是为了强化大家的意识)。在日常开发中,当遇到两段各司其职的代码逻辑时,我们首先要有“尝试拆分”的敏感,其次要有“该不该拆”的判断——当逻辑粒度过小时,盲目拆分会导致你的项目里存在过多的零碎的小方法,这反而不会使我们的代码变得更好。
# # 8. 结构型:装饰器模式——深入装饰器原理与优秀案例
# # 8.1 前置知识:ES7 中的装饰器
在 ES7 中,我们可以像写 python 一样通过一个@语法糖轻松地给一个类装上装饰器:
// 装饰器函数,它的第一个参数是目标类
function classDecorator(target) {
target.hasDecorator = true
return target
}
// 将装饰器“安装”到Button类上
@classDecorator
class Button {
// Button类的相关逻辑
}
// 验证装饰器是否生效
console.log('Button 是否被装饰了:', Button.hasDecorator)
也可以用同样的语法糖去装饰类里面的方法:
// 具体的参数意义,在下个小节,这里大家先感知一下操作
function funcDecorator(target, name, descriptor) {
let originalMethod = descriptor.value
descriptor.value = function() {
console.log('我是Func的装饰器逻辑')
return originalMethod.apply(this, arguments)
}
return descriptor
}
class Button {
@funcDecorator
onClick() {
console.log('我是Func的原有逻辑')
}
}
// 验证装饰器是否生效
const button = new Button()
button.onClick()
注:以上代码直接放进浏览器/Node 中运行会报错,因为浏览器和 Node 目前都不支持装饰器语法,需要大家安装 Babel 进行转码:
安装 Babel 及装饰器相关的 Babel 插件
npm install babel-preset-env babel-plugin-transform-decorators-legacy --save-dev
注:在没有任何配置选项的情况下,babel\-preset\-env 与 babel\-preset\-latest(或者 babel\-preset\-es2015,babel\-preset\-es2016 和 babel\-preset\-es2017 一起)的行为完全相同。
编写配置文件.babelrc:
{
"presets": ["env"],
"plugins": ["transform-decorators-legacy"]
}
最后别忘了下载全局的 Babel 命令行工具用于转码:
npm install babel-cli -g
执行完这波操作,我们首先是对目标文件进行转码,比如说你的目标文件叫做 test.js,想要把它转码后的结果输出到 babel_test.js,就可以这么写:
babel test.js --out-file babel_test.js
运行 babel_test.js
babel_test.js
就可以看到你的装饰器是否生效啦~
OK,知道了装饰器长啥样,我们一起看看装饰器的实现细节:
# # 8.2 装饰器语法糖背后的故事
所谓语法糖,往往意味着“美好的表象”。正如 class 语法糖背后是大家早已十分熟悉的 ES5 构造函数一样,装饰器语法糖背后也是我们的老朋友,不信我们一起来看看@decorator 都帮我们做了些什么:
# # 8.2.1 Part1:函数传参&调用
上一节我们使用 ES6 实现装饰器模式时曾经将按钮实例传给了 Decorator,以便于后续 Decorator 可以对它进行逻辑的拓展。这也正是装饰器的最最基本操作——定义装饰器函数,将被装饰者“交给”装饰器。这也正是装饰器语法糖首先帮我们做掉的工作 —— 函数传参&调用。
类装饰器的参数
当我们给一个类添加装饰器时:
function classDecorator(target) {
target.hasDecorator = true
return target
}
// 将装饰器“安装”到Button类上
@classDecorator
class Button {
// Button类的相关逻辑
}
此处的 target 就是被装饰的类本身。
方法装饰器的参数
而当我们给一个方法添加装饰器时:
function funcDecorator(target, name, descriptor) {
let originalMethod = descriptor.value
descriptor.value = function() {
console.log('我是Func的装饰器逻辑')
return originalMethod.apply(this, arguments)
}
return descriptor
}
class Button {
@funcDecorator
onClick() {
console.log('我是Func的原有逻辑')
}
}
此处的 target 变成了 Button.prototype,即类的原型对象。这是因为 onClick 方法总是要依附其实例存在的,修饰 onClick 其实是修饰它的实例。但我们的装饰器函数执行的时候,Button 实例还并不存在。为了确保实例生成后可以顺利调用被装饰好的方法,装饰器只能去修饰 Button 类的原型对象。
装饰器函数调用的时机
装饰器函数执行的时候,Button 实例还并不存在。这是因为实例是在我们的代码运行时动态生成的,而装饰器函数则是在编译阶段就执行了。所以说装饰器函数真正能触及到的,就只有类这个层面上的对象。
# # 8.2.2 Part2:将“属性描述对象”交到你手里
在编写类装饰器时,我们一般获取一个 target 参数就足够了。但在编写方法装饰器时,我们往往需要至少三个参数:
function funcDecorator(target, name, descriptor) {
let originalMethod = descriptor.value
descriptor.value = function() {
console.log('我是Func的装饰器逻辑')
return originalMethod.apply(this, arguments)
}
return descriptor
}
第一个参数的意义,前文已经解释过。第二个参 数 name,是我们修饰的目标属性属性名,也没啥好讲的。关键就在这个 descriptor 身上,它也是我们使用频率最高的一个参数,它的真面目就是“属性描述对象”(attributes object)。这个名字大家可能不熟悉,但Object.defineProperty方法我想大家多少都用过,它的调用方式是这样的:
Object.defineProperty(obj, prop, descriptor)
此处的 descriptor 和装饰器函数里的 descriptor 是一个东西,它是 JavaScript 提供的一个内部数据结构、一个对象,专门用来描述对象的属性。它由各种各样的属性描述符组成,这些描述符又分为数据描述符和存取描述符:
- 数据描述符:包括 value(存放属性值,默认为默认为 undefined)、writable(表示属性值是否可改变,默认为 true)、enumerable(表示属性是否可枚举,默认为 true)、configurable(属性是否可配置,默认为 true)。
- 存取描述符:包括
get方法(访问属性时调用的方法,默认为 undefined),set(设置属性时调用的方法,默认为 undefined )
很明显,拿到了 descriptor,就相当于拿到了目标方法的控制权。通过修改 descriptor,我们就可以对目标方法的逻辑进行拓展了~
在上文的示例中,我们通过 descriptor 获取到了原函数的函数体(originalMethod),把原函数推迟到了新逻辑(console)的后面去执行。这种做法和我们上一节在 ES5 中实现装饰器模式时做的事情一模一样,所以说装饰器就是这么回事儿,换汤不换药~
# # 8.3 生产实践
装饰器在前端世界的应用十分广泛,即便是在 ES7 未诞生的那些个蛮荒年代,也没能阻挡我们用装饰器开挂的热情。要说优秀的生产实践,可以说是两天两夜也说不完。但有一些实践,我相信大家可能都用过,或者说至少见过、听说过,只是当时并不清楚这个是装饰器模式。此处为了强化大家脑袋里已有的经验与设计模式知识之间的关联,更为了趁热打铁、将装饰器模式常见的用法给大家加固一下,我们一起来看几个不错的生产实践案例:
# # 8.3.1 React 中的装饰器:HOC
高阶组件就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件。
HOC (Higher Order Component) 即高阶组件。它是装饰器模式在 React 中的实践,同时也是 React 应用中非常重要的一部分。通过编写高阶组件,我们可以充分复用现有逻辑,提高编码效率和代码的健壮性。
我们现在编写一个高阶组件,它的作用是把传入的组件丢进一个有红色边框的容器里(拓展其样式)。
import React, { Component } from 'react'
const BorderHoc = WrappedComponent => class extends Component {
render() {
return <div style={{ border: 'solid 1px red' }}>
<WrappedComponent />
</div>
}
}
export default borderHoc
用它来装饰目标组件
import React, { Component } from 'react'
import BorderHoc from './BorderHoc'
// 用BorderHoc装饰目标组件
@BorderHoc
class TargetComponent extends React.Component {
render() {
// 目标组件具体的业务逻辑
}
}
// export出去的其实是一个被包裹后的组件
export default TargetComponent
可以看出,高阶组件从实现层面来看其实就是上文我们提到的类装饰器。在高阶组件的辅助下,我们不必因为一个小小的拓展而大费周折地编写新组件或者把一个新逻辑重写 N 多次,只需要轻轻 @ 一下装饰器即可。
# # 8.3.2 使用装饰器改写 Redux connect
Redux 是热门的状态管理工具。在 React 中,当我们想要引入 Redux 时,通常需要调用 connect 方法来把状态和组件绑在一起:
import React, { Component } from 'react'
import { connect } from 'react-redux'
import { bindActionCreators } from 'redux'
import action from './action.js'
class App extends Component {
render() {
// App的业务逻辑
}
}
function mapStateToProps(state) {
// 假设App的状态对应状态树上的app节点
return state.app
}
function mapDispatchToProps(dispatch) {
// 这段看不懂也没关系,下面会有解释。重点理解connect的调用即可
return bindActionCreators(action, dispatch)
}
// 把App组件与Redux绑在一起
export default connect(mapStateToProps, mapDispatchToProps)(App)
这里给没用过 redux 的同学解释一下 connect 的两个入参:mapStateToProps 是一个函数,它可以建立组件和状态之间的映射关系;mapDispatchToProps也是一个函数,它用于建立组件和store.dispatch的关系,使组件具备通过 dispatch 来派发状态的能力。
总而言之,我们调用 connect 可以返回一个具有装饰作用的函数,这个函数可以接收一 个 React 组件作为参数,使这个目标组件和 Redux 结合、具备 Redux 提供的数据和能力。既然有装饰作用,既然是能力的拓展,那么就一定能用装饰器来改写: 把 connect 抽出来:
import { connect } from 'react-redux'
import { bindActionCreators } from 'redux'
import action from './action.js'
function mapStateToProps(state) {
return state.app
}
function mapDispatchToProps(dispatch) {
return bindActionCreators(action, dispatch)
}
// 将connect调用后的结果作为一个装饰器导出
export default connect(mapStateToProps, mapDispatchToProps)
在组件文件里引入 connect:
import React, { Component } from 'react'
import connect from './connect.js'
@connect
export default class App extends Component {
render() {
// App的业务逻辑
}
}
这样一来,我们的代码结构是不是清晰了很多?可维护性、可读性都上升了一个 level,令人赏心悦目~
Tips: 回忆一下上面一个小节的讲解,对号入座看一看,connect 装饰器从实现和调用方式上来看,是不是同时也是一个高阶组件呢?
# # 8.3.3 优质的源码阅读材料——core-decorators
前面都在教大家怎么写装饰器模式,这里来聊聊怎么用好装饰器模式。
装饰器模式的优势在于其极强的灵活性和可复用性——它本质上是一个函数,而且往往不依赖于任何逻辑而存在。这一点提醒了我们,当我们需要用到某个反复出现的拓展逻辑时,比起自己闷头搞,不如去看一看团队(社区)里有没有现成的实现,如果有,那么贯彻“拿来主义”,直接@就可以了。所以说装饰器模式是个好同志,它可以帮我们省掉大量复制粘贴的时间。
这里就要给大家推荐一个非常赞的装饰模式库 —— core-decorators。core-decorators 帮我们实现好了一些使用频率较高的装饰器,比如@readonly(使目标属性只读)、@deprecate(在控制台输出警告,提示用户某个指定的方法已被废除)等等等等。这里强烈建议大家把 core-decorators 作为自己的源码阅读材料,你能收获的或许比你想象中更多~
# # 9. 结构型:适配器模式——兼容代码就是一把梭
适配器模式通过把一个类的接口变换成客户端所期待的另一种接口,可以帮我们解决不兼容的问题。
# # 9.1 生活中的适配器
前段时间用了很久的 iPhone 6s 丢了,请假跑出去买了台 iPhone X。结果有天听歌的时候发现 X 的耳机孔竟然是方形的,长这样:

而重度 iPhone 6s 用户&耳机发烧友的耳机线,可能是如图一所示,没错,它们都是圆头耳机,意识到这一点的时候,我佛了。
此时我好像只能在重新买一批耳机(很有可能同款耳机并没有方头的款式)和重新买一台手机之间做选择了。好在我不是一个普通的倒霉蛋,我学过设计模式,设计模式告诉我这种实际接口与目标接口不匹配的尴尬可以用一个叫适配器的东西来化解。打开万能的淘宝一搜,还真有,如图二所示。
只要装上它,圆头耳机就可以完美适配方形插槽,最终效果如图三所示。
大家现在回顾楼上这波操作,这个耳机转换头做的事情,是不是就是我们开头说的把一个类(iPhone 新机型)的接口(方形)变换成客户端(用户)所期待的另一种接口(圆形)?
最终达到的效果,就是用户(我)可以像使用 iPhone 6s 插口一样使用 iPhoneX 的插口,而不用感知两者间的差异。我们设计模式中的适配器,和楼上这个适配器做的事情可以说是一模一样,同样具有化腐朽为神奇的力量。
# # 9.2 兼容接口就是一把梭——适配器的业务场景
大家知道我们现在有一个非常好用异步方案叫 fetch,它的写法比 ajax 优雅很多。因此在不考虑兼容性的情况下,我们更愿意使用 fetch、而不是使用 ajax 来发起异步请求。李雷是拜 fetch 教的忠实信徒,为了能更好地使用 fetch,他封装了一个基于 fetch 的 http 方法库:
export default class HttpUtils {
// get方法
static get(url) {
return new Promise((resolve, reject) => {
// 调用fetch
fetch(url)
.then(response => response.json())
.then(result => {
resolve(result)
})
.catch(error => {
reject(error)
})
})
}
// post方法,data以object形式传入
static post(url, data) {
return new Promise((resolve, reject) => {
// 调用fetch
fetch(url, {
method: 'POST',
headers: {
Accept: 'application/json',
'Content-Type': 'application/x-www-form-urlencoded'
},
// 将object类型的数据格式化为合法的body参数
body: this.changeData(data)
})
.then(response => response.json())
.then(result => {
resolve(result)
})
.catch(error => {
reject(error)
})
})
}
// body请求体的格式化方法
static changeData(obj) {
var prop,
str = ''
var i = 0
for (prop in obj) {
if (!prop) {
return
}
if (i == 0) {
str += prop + '=' + obj[prop]
} else {
str += '&' + prop + '=' + obj[prop]
}
i++
}
return str
}
}
当我想使用 fetch 发起请求时,只需要这样轻松地调用,而不必再操心繁琐的数据配置和数据格式化:
// 定义目标url地址
const URL = "xxxxx"
// 定义post入参
const params = {
// ...
}
// 发起post请求
const postResponse = await HttpUtils.post(URL,params) || {}
// 发起get请求
const getResponse = await HttpUtils.get(URL)
真是个好用的方法库!老板看了李雷的 HttpUtils 库,喜上眉梢——原来老板也是个拜 fetch 教。老板说李雷,咱们公司以后要做潮流公司了,写代码不再考虑兼容性,我希望你能把公司所有的业务的网络请求都迁移到你这个 HttpUtils 上来,这样以后你只用维护这一个库了,也方便。李雷一听,悲从中来——他是该公司的第 99 代员工,对远古时期的业务一无所知。而该公司第 1 代员工封装的网络请求库,是基于 XMLHttpRequest 的,差不多长这样:
function Ajax(type, url, data, success, failed){
// 创建ajax对象
var xhr = null;
if(window.XMLHttpRequest){
xhr = new XMLHttpRequest();
} else {
xhr = new ActiveXObject('Microsoft.XMLHTTP')
}
// ...(此处省略一系列的业务逻辑细节)
var type = type.toUpperCase();
// 识别请求类型
if(type == 'GET'){
if(data){
xhr.open('GET', url + '?' + data, true); //如果有数据就拼接
}
// 发送get请求
xhr.send();
} else if(type == 'POST'){
xhr.open('POST', url, true);
// 如果需要像 html 表单那样 POST 数据,使用 setRequestHeader() 来添加 http 头。
xhr.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
// 发送post请求
xhr.send(data);
}
// 处理返回数据
xhr.onreadystatechange = function(){
if(xhr.readyState == 4){
if(xhr.status == 200){
success(xhr.responseText);
} else {
if(failed){
failed(xhr.status);
}
}
}
}
}
实现逻辑我们简单描述了一下,这个不是重点,重点是它是这样调用的:
// 发送get请求
Ajax('get', url地址, post入参, function(data){
// 成功的回调逻辑
}, function(error){
// 失败的回调逻辑
})
李雷佛了 —— 不仅接口名不同,入参方式也不一样,这手动改要改到何年何日呢?
还好李雷学过设计模式,他立刻联想到了专门为我们抹平差异的适配器模式。要把老代码迁移到新接口,不一定要挨个儿去修改每一次的接口调用——正如我们想用 iPhoneX + 旧耳机听歌,不必挨个儿去改造耳机一样,我们只需要在引入接口时进行一次适配,便可轻松地 cover 掉业务里可能会有的多次调用(具体的解析在注释里):
// Ajax适配器函数,入参与旧接口保持一致
async function AjaxAdapter(type, url, data, success, failed) {
const type = type.toUpperCase()
let result
try {
// 实际的请求全部由新接口发起
if(type === 'GET') {
result = await HttpUtils.get(url) || {}
} else if(type === 'POST') {
result = await HttpUtils.post(url, data) || {}
}
// 假设请求成功对应的状态码是1
result.statusCode === 1 && success ? success(result) : failed(result.statusCode)
} catch(error) {
// 捕捉网络错误
if(failed){
failed(error.statusCode);
}
}
}
// 用适配器适配旧的Ajax方法
async function Ajax(type, url, data, success, failed) {
await AjaxAdapter(type, url, data, success, failed)
}
如此一来,我们只需要编写一个适配器函数 AjaxAdapter,并用适配器去承接旧接口的参数,就可以实现新旧接口的无缝衔接了~
# # 9.3 生产实践:axios 中的适配器
数月之后,李雷的老板发现了网络请求神库 axios,于是团队的方案又整个迁移到了 axios——对于心中有适配器的李雷来说,这现在已经根本不是个事儿。不过本小节我们要聊的可不再是“如何使现有接口兼容 axios”了(这招我们上个小节学过了)。此处引出 axios,一是因为大家对它足够熟悉(不熟悉的同学,点这里可以快速熟悉一下~),二是因为 axios 本身就用到了我们的适配器模式,它的兼容方案值得我们学习和借鉴。
在使用 axios 时,作为用户我们只需要掌握以下面三个最常用的接口为代表的一套 api:
// Make a request for a user with a given ID
axios.get('/user?ID=12345')
.then(function (response) {
// handle success
console.log(response);
})
.catch(function (error) {
// handle error
console.log(error);
})
.then(function () {
// always executed
})
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
})
便可轻松地发起各种姿势的网络请求,而不用去关心底层的实现细节。 除了简明优雅的 api 之外,axios 强大的地方还在于,它不仅仅是一个局限于浏览器端的库。在 Node 环境下,我们尝试调用上面的 api,会发现它照样好使 —— axios 完美地抹平了两种环境下 api 的调用差异,靠的正是对适配器模式的灵活运用。
在 axios 的核心逻辑中,我们可以注意到实际上派发请求的是 dispatchRequest 方法。该方法内部其实主要做了两件事:
- 数据转换,转换请求体/响应体,可以理解为数据层面的适配;
- 调用适配器。
调用适配器的逻辑如下:
// 若用户未手动配置适配器,则使用默认的适配器
var adapter = config.adapter || defaults.adapter;
// dispatchRequest方法的末尾调用的是适配器方法
return adapter(config).then(function onAdapterResolution(response) {
// 请求成功的回调
throwIfCancellationRequested(config);
// 转换响应体
response.data = transformData(
response.data,
response.headers,
config.transformResponse
);
return response;
}, function onAdapterRejection(reason) {
// 请求失败的回调
if (!isCancel(reason)) {
throwIfCancellationRequested(config);
// 转换响应体
if (reason && reason.response) {
reason.response.data = transformData(
reason.response.data,
reason.response.headers,
config.transformResponse
);
}
}
return Promise.reject(reason);
});
大家注意注释的第一行,“若用户未手动配置适配器,则使用默认的适配器”。手动配置适配器允许我们自定义处理请求,主要目的是为了使测试更轻松。
实际开发中,我们使用默认适配器的频率更高。默认适配器在axios/lib/default.js里是通过getDefaultAdapter方法来获取的:
function getDefaultAdapter() {
var adapter;
// 判断当前是否是node环境
if (typeof process !== 'undefined' && Object.prototype.toString.call(process) === '[object process]') {
// 如果是node环境,调用node专属的http适配器
adapter = require('./adapters/http');
} else if (typeof XMLHttpRequest !== 'undefined') {
// 如果是浏览器环境,调用基于xhr的适配器
adapter = require('./adapters/xhr');
}
return adapter;
}
我们再来看看 Node 的 http 适配器和 xhr 适配器大概长啥样:
http 适配器:
module.exports = function httpAdapter(config) {
return new Promise(function dispatchHttpRequest(resolvePromise, rejectPromise) {
// 具体逻辑
}
}
xhr 适配器:
module.exports = function xhrAdapter(config) {
return new Promise(function dispatchXhrRequest(resolve, reject) {
// 具体逻辑
}
}
具体逻辑啥样,咱们目前先不关心,有兴趣的同学,可以狠狠地点这里阅读源码。咱们现在就注意两个事儿:
- 两个适配器的入参都是 config;
- 两个适配器的出参都是一个 Promise。
Tips:要是仔细读了源码,会发现两个适配器中的 Promise 的内部结构也是如出一辙。
这么一来,通过 axios 发起跨平台的网络请求,不仅调用的接口名是同一个,连入参、出参的格式都只需要掌握同一套。这导致它的学习成本非常低,开发者看了文档就能上手;同时因为足够简单,在使用的过程中也不容易出错,带来了极佳的用户体验,axios 也因此越来越流行。
这正是一个好的适配器的自我修养——把变化留给自己,把统一留给用户。在此处,所有关于 http 模块、关于 xhr 的实现细节,全部被 Adapter 封装进了自己复杂的底层逻辑里,暴露给用户的都是十分简单的统一的东西——统一的接口,统一的入参,统一的出参,统一的规则。用起来就是一个字 —— 爽!
# # 9.4 小结
适配器模式的思想可以说是遍地开花,稍微多看几个库,你会发现不仅 axios 在用适配器,其它库也在用。如果哪怕只有一个同学因为今天读了这一节,对这个“看起来很厉害”的 axios 产生了好奇,或者说对读源码这件事情萌生了兴趣、进而刻意地去培养了自己的阅读习惯,那么你在繁忙的工作/学业中抽出的宝贵的用来阅读这一节内容的时间就没有白费,这本小册也算不负使命、远远大于它本身的价值了。
# # 10 结构型:代理模式——一家小型婚介所的发家致富之路
代理模式,式如其名——在某些情况下,出于种种考虑/限制,一个对象不能直接访问另一个对象,需要一个第三者(代理)牵线搭桥从而间接达到访问目的,这样的模式就是代理模式。
代理模式非常好理解,因为你可能天天都在用,只是没有刻意挖掘过它背后的玄机——比如大家耳熟能详的科学上网,就是代理模式的典型案例。
# # 10.1 科学上网背后的故事
科学上网,就是咱们常说的 VPN(虚拟专用网络)。大家知道,正常情况下,我们尝试去访问 Google.com,Chrome 会给你一个这样的提示:  这是为啥呢?这就要从网络请求的整个流程说起了。一般情况下,当我们访问一个 url 的时候,会发生下图的过程:
这是为啥呢?这就要从网络请求的整个流程说起了。一般情况下,当我们访问一个 url 的时候,会发生下图的过程:  为了屏蔽某些网站,一股神秘的东方力量会作用于你的 DNS 解析过程,告诉它:“你不能解析出 xxx.xxx.xxx.xxx(某个特殊 ip)的地址”。而我们的 Google.com,不幸地出现在了这串被诅咒的 ip 地址里,于是你的 DNS 会告诉你:“对不起,我查不到”。
为了屏蔽某些网站,一股神秘的东方力量会作用于你的 DNS 解析过程,告诉它:“你不能解析出 xxx.xxx.xxx.xxx(某个特殊 ip)的地址”。而我们的 Google.com,不幸地出现在了这串被诅咒的 ip 地址里,于是你的 DNS 会告诉你:“对不起,我查不到”。
但有时候,一部分人为了搞学习,通过访问 VPN,是可以间接访问到 Google.com 的。这背后,就是代理模式在给力。在使用 VPN 时,我们的访问过程是这样的:

没错,比起常规的访问过程,多出了一个第三方 —— 代理服务器。这个第三方的 ip 地址,不在被禁用的那批 ip 地址之列,我们可以顺利访问到这台服务器。而这台服务器的 DNS 解析过程,没有被施加咒语,所以它是可以顺利访问 Google.com 的。代理服务器在请求到 Google.com 后,将响应体转发给你,使你得以间接地访问到目标网址 —— 像这种第三方代替我们访问目标对象的模式,就是代理模式。
# # 10.2 用代理模式开一家婚姻介绍所吧
这样看来,开婚介所确实是个发家致富的好路子。既然暴富的机会就在眼前,那么事不宜迟,我们接下来就一起用 JavaScript 来实现一个小型婚介所。
# # 10.2.1 前置知识: ES6 中的 Proxy
前置知识: ES6 中的 Proxy
const proxy = new Proxy(obj, handler)
第一个参数是我们的目标对象,也就是上文中的“未知妹子”。handler 也是一个对象,用来定义代理的行为,相当于上文中的“婚介所”。当我们通过 proxy 去访问目标对象的时候,handler 会对我们的行为作一层拦截,我们的每次访问都需要经过 handler 这个第三方。
# # 10.2.2 “婚介所”的实现
未知妹子的个人信息,刚问了下我们已经注册了 VIP 的同事哥,大致如下:
// 未知妹子
const girl = {
// 姓名
name: '小美',
// 自我介绍
aboutMe: '...'(大家自行脑补吧)
// 年龄
age: 24,
// 职业
career: 'teacher',
// 假头像
fakeAvatar: 'xxxx'(新垣结衣的图片地址)
// 真实头像
avatar: 'xxxx'(自己的照片地址),
// 手机号
phone: 123456,
}
婚介所收到了小美的信息,开始营业。大家想,这个姓名、自我介绍、假头像,这些信息大差不差,曝光一下没问题。但是人家妹子的年龄、职业、真实头像、手机号码,是不是属于非常私密的信息了?要想 get 这些信息,平台要考验一下你的诚意了 —— 首先,你是不是已经通过了实名审核?如果通过实名审核,那么你可以查看一些相对私密的信息(年龄、职业)。然后,你是不是 VIP ?只有 VIP 可以查看真实照片和联系方式。满足了这两个判定条件,你才可以顺利访问到别人的全部私人信息,不然,就劝退你提醒你去完成认证和 VIP 购买再来。
// 普通私密信息
const baseInfo = ['age', 'career']
// 最私密信息
const privateInfo = ['avatar', 'phone']
// 用户(同事A)对象实例
const user = {
// ...(一些必要的个人信息)
isValidated: true,
isVIP: false,
}
// 掘金婚介所登场了
const JuejinLovers = new Proxy(girl, {
get: function(girl, key) {
if(baseInfo.indexOf(key)!==-1 && !user.isValidated) {
alert('您还没有完成验证哦')
return
}
//...(此处省略其它有的没的各种校验逻辑)
// 此处我们认为只有验证过的用户才可以购买VIP
if(user.isValidated && privateInfo.indexOf(key) && !user.isVIP) {
alert('只有VIP才可以查看该信息哦')
return
}
}
})
以上主要是 getter 层面的拦截。假设我们还允许会员间互送礼物,每个会员可以告知婚介所自己愿意接受的礼物的价格下限,我们还可以作 setter 层面的拦截。:
// 规定礼物的数据结构由type和value组成
const present = {
type: '巧克力',
value: 60,
}
// 为用户增开presents字段存储礼物
const girl = {
// 姓名
name: '小美',
// 自我介绍
aboutMe: '...'(大家自行脑补吧)
// 年龄
age: 24,
// 职业
career: 'teacher',
// 假头像
fakeAvatar: 'xxxx'(新垣结衣的图片地址)
// 真实头像
avatar: 'xxxx'(自己的照片地址),
// 手机号
phone: 123456,
// 礼物数组
presents: [],
// 拒收50块以下的礼物
bottomValue: 50,
// 记录最近一次收到的礼物
lastPresent: present,
}
// 掘金婚介所推出了小礼物功能
const JuejinLovers = new Proxy(girl, {
get: function(girl, key) {
if(baseInfo.indexOf(key)!==-1 && !user.isValidated) {
alert('您还没有完成验证哦')
return
}
//...(此处省略其它有的没的各种校验逻辑)
// 此处我们认为只有验证过的用户才可以购买VIP
if(user.isValidated && privateInfo.indexOf(key) && !user.isVIP) {
alert('只有VIP才可以查看该信息哦')
return
}
}
set: function(girl, key, val) {
// 最近一次送来的礼物会尝试赋值给lastPresent字段
if(key === 'lastPresent') {
if(val.value < girl.bottomValue) {
alert('sorry,您的礼物被拒收了')
return
}
// 如果没有拒收,则赋值成功,同时并入presents数组
girl[lastPresent] = val
girl[presents] = [...presents, val]
}
}
})
不过如果认为代理模式的本领仅仅是开个婚介所这么简单,那就太小瞧它了。代理模式在前端领域一直是一种应用十分广泛的设计模式
# # 11 结构型:代理模式——应用实践范例解析
本节我们选取业务开发中最常见的四种代理类型:事件代理、虚拟代理、缓存代理和保护代理来进行讲解。
在实际开发中,代理模式和我们下节要讲的“大 Boss ”观察者模式一样,可以玩出花来。但设计模式这玩意儿就是这样,变体再多、玩得再花,它的核心操作都是死的,套路也是死的——正是这种极强的规律性带来了极高的性价比。相信学完这节后,大家对这点会有更深的感触。
# # 11.1 事件代理
事件代理,可能是代理模式最常见的一种应用方式,也是一道实打实的高频面试题。它的场景是一个父元素下有多个子元素,像这样:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>事件代理</title>
</head>
<body>
<div id="father">
<a href="#">链接1号</a>
<a href="#">链接2号</a>
<a href="#">链接3号</a>
<a href="#">链接4号</a>
<a href="#">链接5号</a>
<a href="#">链接6号</a>
</div>
</body>
</html>
我们现在的需求是,希望鼠标点击每个 a 标签,都可以弹出“我是 xxx”这样的提示。比如点击第一个 a 标签,弹出“我是链接 1 号”这样的提示。这意味着我们至少要安装 6 个监听函数给 6 个不同的的元素(一般我们会用循环,代码如下所示),如果我们的 a 标签进一步增多,那么性能的开销会更大。
// 假如不用代理模式,我们将循环安装监听函数
const aNodes = document.getElementById('father').getElementsByTagName('a')
const aLength = aNodes.length
for(let i=0;i<aLength;i++) {
aNodes[i].addEventListener('click', function(e) {
e.preventDefault()
alert(`我是${aNodes[i].innerText}`)
})
}
考虑到事件本身具有“冒泡”的特性,当我们点击 a 元素时,点击事件会“冒泡”到父元素 div 上,从而被监听到。如此一来,点击事件的监听函数只需要在 div 元素上被绑定一次即可,而不需要在子元素上被绑定 N 次——这种做法就是事件代理,它可以很大程度上提高我们代码的性能。
事件代理的实现
用代理模式实现多个子元素的事件监听,代码会简单很多:
// 获取父元素
const father = document.getElementById('father')
// 给父元素安装一次监听函数
father.addEventListener('click', function(e) {
// 识别是否是目标子元素
if(e.target.tagName === 'A') {
// 以下是监听函数的函数体
e.preventDefault()
alert(`我是${e.target.innerText}`)
}
})
在这种做法下,我们的点击操作并不会直接触及目标子元素,而是由父元素对事件进行处理和分发、间接地将其作用于子元素,因此这种操作从模式上划分属于代理模式。
# # 11.2 虚拟代理
我们此处简单地给大家描述一下懒加载是个什么东西:它是针对图片加载时机的优化:在一些图片量比较大的网站,比如电商网站首页,或者团购网站、小游戏首页等。如果我们尝试在用户打开页面的时候,就把所有的图片资源加载完毕,那么很可能会造成白屏、卡顿等现象。
此时我们会采取“先占位、后加载”的方式来展示图片 —— 在元素露出之前,我们给它一个 div 作占位,当它滚动到可视区域内时,再即时地去加载真实的图片资源,这样做既减轻了性能压力、又保住了用户体验。
除了图片懒加载,还有一种操作叫图片预加载。预加载主要是为了避免网络不好、或者图片太大时,页面长时间给用户留白的尴尬。常见的操作是先让这个 img 标签展示一个占位图,然后创建一个 Image 实例,让这个 Image 实例的 src 指向真实的目标图片地址、观察该 Image 实例的加载情况 —— 当其对应的真实图片加载完毕后,即已经有了该图片的缓存内容,再将 DOM 上的 img 元素的 src 指向真实的目标图片地址。此时我们直接去取了目标图片的缓存,所以展示速度会非常快,从占位图到目标图片的时间差会非常小、小到用户注意不到,这样体验就会非常好了。
上面的思路,我们可以不假思索地实现如下
class PreLoadImage {
// 占位图的url地址
static LOADING_URL = 'xxxxxx'
constructor(imgNode) {
// 获取该实例对应的DOM节点
this.imgNode = imgNode
}
// 该方法用于设置真实的图片地址
setSrc(targetUrl) {
// img节点初始化时展示的是一个占位图
this.imgNode.src = PreLoadImage.LOADING_URL
// 创建一个帮我们加载图片的Image实例
const image = new Image()
// 监听目标图片加载的情况,完成时再将DOM上的img节点的src属性设置为目标图片的url
image.onload = () => {
this.imgNode.src = targetUrl
}
// 设置src属性,Image实例开始加载图片
image.src = srcUrl
}
}
这个 PreLoadImage 乍一看没问题,但其实违反了我们设计原则中的单一职责原则。PreLoadImage 不仅要负责图片的加载,还要负责 DOM 层面的操作(img 节点的初始化和后续的改变)。这样一来,就出现了两个可能导致这个类发生变化的原因。
好的做法是将两个逻辑分离,让 PreLoadImage 专心去做 DOM 层面的事情(真实 DOM 节点的获取、img 节点的链接设置),再找一个对象来专门来帮我们搞加载——这两个对象之间缺个媒婆,这媒婆非代理器不可:
class PreLoadImage {
constructor(imgNode) {
// 获取真实的DOM节点
this.imgNode = imgNode
}
// 操作img节点的src属性
setSrc(imgUrl) {
this.imgNode.src = imgUrl
}
}
class ProxyImage {
// 占位图的url地址
static LOADING_URL = 'xxxxxx'
constructor(targetImage) {
// 目标Image,即PreLoadImage实例
this.targetImage = targetImage
}
// 该方法主要操作虚拟Image,完成加载
setSrc(targetUrl) {
// 真实img节点初始化时展示的是一个占位图
this.targetImage.setSrc(ProxyImage.LOADING_URL)
// 创建一个帮我们加载图片的虚拟Image实例
const virtualImage = new Image()
// 监听目标图片加载的情况,完成时再将DOM上的真实img节点的src属性设置为目标图片的url
virtualImage.onload = () => {
this.targetImage.setSrc(targetUrl)
}
// 设置src属性,虚拟Image实例开始加载图片
virtualImage.src = targetUrl
}
}
ProxyImage 帮我们调度了预加载相关的工作,我们可以通过 ProxyImage 这个代理,实现对真实 img 节点的间接访问,并得到我们想要的效果。
在这个实例中,virtualImage 这个对象是一个“幕后英雄”,它始终存在于 JavaScript 世界中、代替真实 DOM 发起了图片加载请求、完成了图片加载工作,却从未在渲染层面抛头露面。因此这种模式被称为“虚拟代理”模式。
# # 11.3 缓存代理
缓存代理比较好理解,它应用于一些计算量较大的场景里。在这种场景下,我们需要“用空间换时间”——当我们需要用到某个已经计算过的值的时候,不想再耗时进行二次计算,而是希望能从内存里去取出现成的计算结果。这种场景下,就需要一个代理来帮我们在进行计算的同时,进行计算结果的缓存了。
一个比较典型的例子,是对传入的参数进行求和:
// addAll方法会对你传入的所有参数做求和操作
const addAll = function() {
console.log('进行了一次新计算')
let result = 0
const len = arguments.length
for(let i = 0; i < len; i++) {
result += arguments[i]
}
return result
}
// 为求和方法创建代理
const proxyAddAll = (function(){
// 求和结果的缓存池
const resultCache = {}
return function() {
// 将入参转化为一个唯一的入参字符串
const args = Array.prototype.join.call(arguments, ',')
// 检查本次入参是否有对应的计算结果
if(args in resultCache) {
// 如果有,则返回缓存池里现成的结果
return resultCache[args]
}
return resultCache[args] = addAll(...arguments)
}
})()
我们把这个方法丢进控制台,尝试同一套入参两次,结果喜人:  我们发现 proxyAddAll 针对重复的入参只会计算一次,这将大大节省计算过程中的时间开销。现在我们有 6 个入参,可能还看不出来,当我们针对大量入参、做反复计算时,缓存代理的优势将得到更充分的凸显。
我们发现 proxyAddAll 针对重复的入参只会计算一次,这将大大节省计算过程中的时间开销。现在我们有 6 个入参,可能还看不出来,当我们针对大量入参、做反复计算时,缓存代理的优势将得到更充分的凸显。
# # 11.4 保护代理
保护代理,其实在我们上个小节大家就见识过了。此处我们仅作提点,不作重复演示。
开婚介所的时候,为了保护用户的私人信息,我们会在同事哥访问小美的年龄的时候,去校验同事哥是否已经通过了我们的实名认证;为了确保婚介所的利益同事哥确实是一位有诚意的男士,当他想获取小美的联系方式时,我们会校验他是否具有 VIP 资格。所谓“保护代理”,就是在访问层面做文章,在 getter 和 setter 函数里去进行校验和拦截,确保一部分变量是安全的。
值得一提的是,上节中我们提到的 Proxy,它本身就是为拦截而生的,所以我们目前实现保护代理时,考虑的首要方案就是 ES6 中的 Proxy。
# # 12. 行为型:策略模式——重构小能手,拆分“胖逻辑”
策略模式和状态模式属于本书”彩蛋“性质的附加小节。这两种模式理解难度都不大,在面试中也几乎没有什么权重,但是却对大家培养良好的编码习惯和重构意识却大有裨益。针对这两种模式,大家了解、会用即可,不建议大家死磕。
策略模式不太适合一上来就怼概念,容易懵。咱们就先从一个非常贴近业务的需求讲起,大家跟我一起敲完这波代码,自然会知道策略模式是怎么回事儿了。
# # 12.1 先来看一个真实场景
有一天,产品经理韩梅梅找到李雷,给李雷提了这么个需求: 马上大促要来了,我们本次大促要做差异化询价。啥是差异化询价?就是说同一个商品,我通过在后台给它设置不同的价格类型,可以让它展示不同的价格。具体的逻辑如下:
- 当价格类型为“预售价”时,满 100 - 20,不满 100 打 9 折
- 当价格类型为“大促价”时,满 100 - 30,不满 100 打 8 折
- 当价格类型为“返场价”时,满 200 - 50,不叠加
- 当价格类型为“尝鲜价”时,直接打 5 折
李雷扫了一眼 prd,立刻来了主意。他首先将四种价格做了标签化:
预售价 - pre
大促价 - onSale
返场价 - back
尝鲜价 - fresh
接下来李雷仔细研读了 prd 的内容,作为资深 if-else 侠,他三下五除二就写出一套功能完备的代码:
// 询价方法,接受价格标签和原价为入参
function askPrice(tag, originPrice) {
// 处理预热价
if(tag === 'pre') {
if(originPrice >= 100) {
return originPrice - 20
}
return originPrice * 0.9
}
// 处理大促价
if(tag === 'onSale') {
if(originPrice >= 100) {
return originPrice - 30
}
return originPrice * 0.8
}
// 处理返场价
if(tag === 'back') {
if(originPrice >= 200) {
return originPrice - 50
}
return originPrice
}
// 处理尝鲜价
if(tag === 'fresh') {
return originPrice * 0.5
}
}
# # 12.2 if-else 侠,人人喊打
随便跑一下,上述代码运行起来确实没啥毛病。但也只是“运行起来”没毛病而已。作为人人喊打的 if-else 侠,李雷必须为他的行为付出代价。我们一起来看看这么写代码会带来什么后果:
- 首先,它违背了“单一功能”原则。一个 function 里面,它竟然处理了四坨逻辑——这个函数的逻辑太胖了!这样会带来什么样的糟糕后果,笔者在前面的小节中已经 BB 过很多次了:比如说万一其中一行代码出了 Bug,那么整个询价逻辑都会崩坏;与此同时出了 Bug 你很难定位到底是哪个代码块坏了事;再比如说单个能力很难被抽离复用等等等等。相信跟着我一路学下来的各位,也已经在重重实战中对胖逻辑的恶劣影响有了切身的体会。总之,见到胖逻辑,我们的第一反应,就是一个字——拆!
- 不仅如此,它还违背了“开放封闭”原则。假如有一天韩梅梅再次找到李雷,要他加一个满 100 - 50 的“新人价”怎么办?他只能继续 if-else:
function askPrice(tag, originPrice) {
// 处理预热价
if(tag === 'pre') {
if(originPrice >= 100) {
return originPrice - 20
}
return originPrice * 0.9
}
// 处理大促价
if(tag === 'onSale') {
if(originPrice >= 100) {
return originPrice - 30
}
return originPrice * 0.8
}
// 处理返场价
if(tag === 'back') {
if(originPrice >= 200) {
return originPrice - 50
}
return originPrice
}
// 处理尝鲜价
if(tag === 'fresh') {
return originPrice * 0.5
}
// 处理新人价
if(tag === 'newUser') {
if(originPrice >= 100) {
return originPrice - 50
}
return originPrice
}
}
没错,李雷灰溜溜地跑去改了 askPrice 函数!随后他恬不知耻地徐徐转头,对背后的测试同学说:哥,我改了询价函数,麻烦你帮我把整个询价逻辑回归一下。测试同学莞尔一笑, 心中早已有无数头羊驼在狂奔。他强忍着周末加班的悲痛,做完了这漫长而不必要的回归测试,随后对李雷说:哥,求你学学设计模式吧!!
# # 12.3 重构询价逻辑
现在我们基于我们已经学过的设计模式思想,一点一点改造掉这个臃肿的 askPrice。
单一功能改造
首先,我们赶紧把四种询价逻辑提出来,让它们各自为政:
// 处理预热价
function prePrice(originPrice) {
if(originPrice >= 100) {
return originPrice - 20
}
return originPrice * 0.9
}
// 处理大促价
function onSalePrice(originPrice) {
if(originPrice >= 100) {
return originPrice - 30
}
return originPrice * 0.8
}
// 处理返场价
function backPrice(originPrice) {
if(originPrice >= 200) {
return originPrice - 50
}
return originPrice
}
// 处理尝鲜价
function freshPrice(originPrice) {
return originPrice * 0.5
}
function askPrice(tag, originPrice) {
// 处理预热价
if(tag === 'pre') {
return prePrice(originPrice)
}
// 处理大促价
if(tag === 'onSale') {
return onSalePrice(originPrice)
}
// 处理返场价
if(tag === 'back') {
return backPrice(originPrice)
}
// 处理尝鲜价
if(tag === 'fresh') {
return freshPrice(originPrice)
}
}
OK,我们现在至少做到了一个函数只做一件事。现在每个函数都有了自己明确的、单一的分工:
prePrice - 处理预热价
onSalePrice - 处理大促价
backPrice - 处理返场价
freshPrice - 处理尝鲜价
askPrice - 分发询价逻辑
如此一来,我们在遇到 Bug 时,就可以做到“头痛医头,脚痛医脚”,而不必在庞大的逻辑海洋里费力去定位到底是哪块不对。
同时,如果我在另一个函数里也想使用某个询价能力,比如说我想询预热价,那我直接把 prePrice 这个函数拿去调用就是了,而不必在 askPrice 肥胖的身躯里苦苦寻觅、然后掏出这块逻辑、最后再复制粘贴到另一个函数去——更何况万一哪天 askPrice 里的预热价逻辑改了,你还得再复制粘贴一次,扎心啊老铁!
到这里,在单一功能原则的指引下,我们已经解决了一半的问题。
我们现在来捋一下,其实这个询价逻辑整体上来看只有两个关键动作:
询价逻辑的分发 ——> 询价逻辑的执行
在改造的第一步,我们已经把“询价逻辑的执行”给摘了出去,并且实现了不同询价逻辑之间的解耦。接下来,我们就要拿“分发”这个动作开刀。
开放封闭改造
剩下一半的问题是啥呢?就是咱们上面说的那个新人价的问题——这会儿我要想给 askPrice 增加新人询价逻辑,我该咋整?我只能这么来:
// 处理预热价
function prePrice(originPrice) {
if(originPrice >= 100) {
return originPrice - 20
}
return originPrice * 0.9
}
// 处理大促价
function onSalePrice(originPrice) {
if(originPrice >= 100) {
return originPrice - 30
}
return originPrice * 0.8
}
// 处理返场价
function backPrice(originPrice) {
if(originPrice >= 200) {
return originPrice - 50
}
return originPrice
}
// 处理尝鲜价
function freshPrice(originPrice) {
return originPrice * 0.5
}
// 处理新人价
function newUserPrice(originPrice) {
if(originPrice >= 100) {
return originPrice - 50
}
return originPrice
}
function askPrice(tag, originPrice) {
// 处理预热价
if(tag === 'pre') {
return prePrice(originPrice)
}
// 处理大促价
if(tag === 'onSale') {
return onSalePrice(originPrice)
}
// 处理返场价
if(tag === 'back') {
return backPrice(originPrice)
}
// 处理尝鲜价
if(tag === 'fresh') {
return freshPrice(originPrice)
}
// 处理新人价
if(tag === 'newUser') {
return newUserPrice(originPrice)
}
}
在外层,我们编写一个 newUser 函数用于处理新人价逻辑;在 askPrice 里面,我们新增了一个 if-else 判断。可以看出,这样其实还是在修改 askPrice 的函数体,没有实现“对扩展开放,对修改封闭”的效果。
那么我们应该怎么做?我们仔细想想,楼上用了这么多 if-else,我们的目的到底是什么?是不是就是为了把 询价标签-询价函数 这个映射关系给明确下来?那么在 JS 中,有没有什么既能够既帮我们明确映射关系,同时不破坏代码的灵活性的方法呢?答案就是对象映射!
咱们完全可以把询价算法全都收敛到一个对象里去嘛:
// 定义一个询价处理器对象
const priceProcessor = {
pre(originPrice) {
if (originPrice >= 100) {
return originPrice - 20;
}
return originPrice * 0.9;
},
onSale(originPrice) {
if (originPrice >= 100) {
return originPrice - 30;
}
return originPrice * 0.8;
},
back(originPrice) {
if (originPrice >= 200) {
return originPrice - 50;
}
return originPrice;
},
fresh(originPrice) {
return originPrice * 0.5;
},
};
当我们想使用其中某个询价算法的时候:通过标签名去定位就好了:
// 询价函数
function askPrice(tag, originPrice) {
return priceProcessor[tag](originPrice)
}
如此一来,askPrice 函数里的 if-else 大军彻底被咱们消灭了。这时候如果你需要一个新人价,只需要给 priceProcessor 新增一个映射关系:
priceProcessor.newUser = function (originPrice) {
if (originPrice >= 100) {
return originPrice - 50;
}
return originPrice;
}
这样一来,询价逻辑的分发也变成了一个清清爽爽的过程。当李雷以这种方式新增一个新人价的询价逻辑的时候,就可以底气十足地对测试同学说:老哥,我改了询价逻辑,但是改动范围仅仅涉及到新人价,是一个单纯的功能增加。所以你只测这个新功能点就 OK,老逻辑不用管!
从此,李雷就从人人喊打的 if-else 侠,摇身一变成为了测试之友、中国好开发。业务代码里的询价逻辑,也因为李雷坚守设计原则 100 年不动摇,而变得易读、易维护。
# # 12.4 这,就是策略模式!
说起来你可能不相信,咱们上面的整个重构的过程,就是对策略模式的应用。 现在大家来品品策略模式的定义:
定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
回头看看,咱们忙活到现在,是不是就干了这事儿?
但你要直接读这句话,可能确实会懵圈——啥是算法?如何封装?可替换又是咋做到的?
如今你你已经自己动手实现了算法提取、算法封装、分发优化的整个一条龙的操作流,相信面对这条定义,你可以会心一笑——算法,就是我们这个场景中的询价逻辑,它也可以是你任何一个功能函数的逻辑;“封装”就是把某一功能点对应的逻辑给提出来;“可替换”建立在封装的基础上,只是说这个“替换”的判断过程,咱们不能直接怼 if-else,而要考虑更优的映射方案。
# # 13. 状态模式
状态模式和策略模式宛如一对孪生兄弟——它们长得很像、解决的问题也可以说没啥本质上的差别。虽然现在的你可能和本书的主人公李雷一样,对状态模式怀揣着一种“我没见过你所以我觉得你一定很牛 x”的敬畏之心。不过没关系,随着我们本节学习过程的展开,你会慢慢体会到状态模式带来的快乐~
# # 13.1 一杯咖啡带来的思考
# # 13.2 一台咖啡机的诞生
作为一个具备强大抽象思维能力的程序员,李雷没有辜负自己这么多年来学过的现代前端框架。他敏锐地感知到,韩梅梅所说的这些不同的”选择“间的切换,本质就是状态的切换。在这个能做四种咖啡的咖啡机体内,蕴含着四种状态:
- 美式咖啡态(american):只吐黑咖啡
- 普通拿铁态(latte):黑咖啡加点奶
- 香草拿铁态(vanillaLatte):黑咖啡加点奶再加香草糖浆
- 摩卡咖啡态(mocha):黑咖啡加点奶再加点巧克力
嘿嘿,这么一梳理,李雷的思路一下子清晰了起来。作为死性不改的 if-else 侠,他再次三下五除二写出了一套功能完备的代码:
class CoffeeMaker {
constructor() {
/**
这里略去咖啡机中与咖啡状态切换无关的一些初始化逻辑
**/
// 初始化状态,没有切换任何咖啡模式
this.state = 'init';
}
// 关注咖啡机状态切换函数
changeState(state) {
// 记录当前状态
this.state = state;
if(state === 'american') {
// 这里用 console 代指咖啡制作流程的业务逻辑
console.log('我只吐黑咖啡');
} else if(state === 'latte') {
console.log(`给黑咖啡加点奶`);
} else if(state === 'vanillaLatte') {
console.log('黑咖啡加点奶再加香草糖浆');
} else if(state === 'mocha') {
console.log('黑咖啡加点奶再加点巧克力');
}
}
}
测试一下,完美无缺:
const mk = new CoffeeMaker();
mk.changeState('latte'); // 输出 '给黑咖啡加点奶'
# # 13.3 不,我李雷必不可能再做 if-else 侠
鉴于 if-else 使不得,李雷赶紧翻出了他在策略模式中学到的“单一职责”和“开放封闭”原则,比猫画虎地改造起了自己的咖啡机:
# # 13.4 改造咖啡机的状态切换机制
职责分离
首先,映入李雷眼帘最大的问题,就是咖啡制作过程不可复用:
changeState(state) {
// 记录当前状态
this.state = state;
if(state === 'american') {
// 这里用 console 代指咖啡制作流程的业务逻辑
console.log('我只吐黑咖啡');
} else if(state === 'latte') {
console.log(`给黑咖啡加点奶`);
} else if(state === 'vanillaLatte') {
console.log('黑咖啡加点奶再加香草糖浆');
} else if(state === 'mocha') {
console.log('黑咖啡加点奶再加点巧克力');
}
}
李雷发现,这个 changeState 函数,它好好管好自己的事(状态切换)不行吗?怎么连做咖啡的过程也写在这里面?这不合理。
别的不说,就说咱李雷和韩梅梅都欲罢不能的香草拿铁吧:它是啥高深莫测的新品种么?它不是,它就是拿铁加点糖浆。那我至于把做拿铁的逻辑再在香草拿铁里写一遍么——完全不需要!直接调用拿铁制作工序对应的函数,然后末尾补个加糖浆的动作就行了——可惜,我们现在所有的制作工序都没有提出来函数化,而是以一种极不优雅的姿势挤在了 changeState 里面,谁也别想复用谁。太费劲了,咱们赶紧给它搞一搞职责分离:
class CoffeeMaker {
constructor() {
/**
这里略去咖啡机中与咖啡状态切换无关的一些初始化逻辑
**/
// 初始化状态,没有切换任何咖啡模式
this.state = 'init';
}
changeState(state) {
// 记录当前状态
this.state = state;
if(state === 'american') {
// 这里用 console 代指咖啡制作流程的业务逻辑
this.americanProcess();
} else if(state === 'latte') {
this.latteProcress();
} else if(state === 'vanillaLatte') {
this.vanillaLatteProcress();
} else if(state === 'mocha') {
this.mochaProcress();
}
}
americanProcess() {
console.log('我只吐黑咖啡');
}
latteProcress() {
this.americanProcess();
console.log('加点奶');
}
vanillaLatteProcress() {
this.latteProcress();
console.log('再加香草糖浆');
}
mochaProcress() {
this.latteProcress();
console.log('再加巧克力');
}
}
const mk = new CoffeeMaker();
mk.changeState('latte');
输出结果符合预期:
我只吐黑咖啡
加点奶
开放封闭
复用的问题解决了,if-else 却仍然活得好好的。
现在咱们假如要增加”气泡美式“这个咖啡品种,就不得不去修改 changeState 的函数逻辑,这违反了开放封闭的原则。
同时,一个函数里收敛这么多判断,也着实不够体面。咱们现在要像策略模式一样,想办法把咖啡机状态和咖啡制作工序之间的映射关系(也就是咱们上节谈到的分发过程)用一个更优雅地方式做掉。如果你策略模式掌握得足够好,你会第一时间反映出对象映射的方案:
const stateToProcessor = {
american() {
console.log('我只吐黑咖啡');
},
latte() {
this.american();
console.log('加点奶');
},
vanillaLatte() {
this.latte();
console.log('再加香草糖浆');
},
mocha() {
this.latte();
console.log('再加巧克力');
}
}
class CoffeeMaker {
constructor() {
/**
这里略去咖啡机中与咖啡状态切换无关的一些初始化逻辑
**/
// 初始化状态,没有切换任何咖啡模式
this.state = 'init';
}
// 关注咖啡机状态切换函数
changeState(state) {
// 记录当前状态
this.state = state;
// 若状态不存在,则返回
if(!stateToProcessor[state]) {
return ;
}
stateToProcessor[state]();
}
}
const mk = new CoffeeMaker();
mk.changeState('latte');
输出结果符合预期:
我只吐黑咖啡
加点奶
当我们这么做时,其实已经实现了一个 js 版本的状态模式。
但这里有一点大家需要引起注意:这种方法仅仅是看上去完美无缺,其中却暗含一个非常重要的隐患——stateToProcessor 里的工序函数,感知不到咖啡机的内部状况。
策略与状态的辨析
怎么理解这个问题?大家知道,策略模式是对算法的封装。算法和状态对应的行为函数虽然本质上都是行为,但是算法的独立性可高多了。
比如说我一个询价算法,我只需要读取一个数字,我就能啪啪三下五除二给你吐出另一个数字作为返回结果——它和计算主体之间可以是分离的,我们只要关注计算逻辑本身就可以了。
但状态可不一样了。拿咱们咖啡机来说,为了好懂,咱写代码的时候把真正咖啡的制作工序用 console 来表示了。但大家都知道,做咖啡要考虑的东西可太多了。 比如咱们做拿铁,拿铁里的牛奶从哪来,是不是从咖啡机的某个储物空间里去取?再比如我们行为函数是不是应该时刻感知咖啡机每种原材料的用量、进而判断自己的工序还能不能如期执行下去?这就决定了行为函数必须能很方便地拿到咖啡机这个主体的各种信息——它必须得对主体有感知才行。
策略模式和状态模式确实是相似的,它们都封装行为、都通过委托来实现行为分发。
但策略模式中的行为函数是”潇洒“的行为函数,它们不依赖调用主体、互相平行、各自为政,井水不犯河水。而状态模式中的行为函数,首先是和状态主体之间存在着关联,由状态主体把它们串在一起;另一方面,正因为关联着同样的一个(或一类)主体,所以不同状态对应的行为函数可能并不会特别割裂。
进一步改造
按照我们这一通描述,当务之急是要把咖啡机和它的状态处理函数建立关联。
如果你读过一些早期的设计模式教学资料,有一种思路是将每一个状态所对应的的一些行为抽象成类,然后通过传递 this 的方式来关联状态和状态主体。 这种思路也可以,不过它一般还需要你实现抽象工厂,比较麻烦。实际业务中这种做法极为少见。我这里要给大家介绍的是一种更方便也更常用的解决方案——非常简单,把状态-行为映射对象作为主体类对应实例的一个属性添加进去就行了:
class CoffeeMaker {
constructor() {
/**
这里略去咖啡机中与咖啡状态切换无关的一些初始化逻辑
**/
// 初始化状态,没有切换任何咖啡模式
this.state = 'init';
// 初始化牛奶的存储量
this.leftMilk = '500ml';
}
stateToProcessor = {
that: this,
american() {
// 尝试在行为函数里拿到咖啡机实例的信息并输出
console.log('咖啡机现在的牛奶存储量是:', this.that.leftMilk)
console.log('我只吐黑咖啡');
},
latte() {
this.american()
console.log('加点奶');
},
vanillaLatte() {
this.latte();
console.log('再加香草糖浆');
},
mocha() {
this.latte();
console.log('再加巧克力');
}
}
// 关注咖啡机状态切换函数
changeState(state) {
this.state = state;
if (!this.stateToProcessor[state]) {
return;
}
this.stateToProcessor[state]();
}
}
const mk = new CoffeeMaker();
mk.changeState('latte');
输出结果为:
咖啡机现在的牛奶存储量是: 500ml
我只吐黑咖啡
加点奶
如此一来,我们就可以在 stateToProcessor 轻松拿到咖啡机的实例对象,进而感知咖啡机这个主体了。
# # 13.5 状态模式复盘
和策略模式一样,咱们仍然是敲完代码之后,一起来复盘一下状态模式的定义:
状态模式(State Pattern) :允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。
这个定义比较粗糙,可能你读完仍然 get 不到它想让你干啥。这时候,我们就应该把目光转移到它解决的问题上来:
状态模式主要解决的是当控制一个对象状态的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类中,可以把复杂的判断逻辑简化。
仔细回忆一下我们这节做的事情,也确实就是这么回事儿。
唯一的区别在于,定义里强调了”类“的概念。但我们的示例中,包括大家今后的实践中,一个对象的状态如果复杂到了你不得不给它的每 N 种状态划分为一类、一口气划分很多类这种程度,我更倾向于你去反思一个这个对象是不是做太多事情了。事实上,在大多数场景下,我们的行为划分,都是可以像本节一样,控制在”函数“这个粒度的。
# # 14 行为型:观察者模式——鬼故事:产品经理拉了一个钉钉群
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个目标对象,当这个目标对象的状态发生变化时,会通知所有观察者对象,使它们能够自动更新。 —— Graphic Design Patterns
观察者模式,是所有 JavaScript 设计模式中使用频率最高,面试频率也最高的设计模式,所以说它十分重要——如果我是面试官,考虑到面试时间有限、设计模式这块不能多问,我可能在考查你设计模式的时候只会问观察者模式这一个模式。该模式的权重极高,我们此处会花费两个较长的章节把它掰碎嚼烂了来掌握。
重点不一定是难点。观察者模式十分重要,但它并不抽象,理解难度不大。这种模式不仅在业务开发中遍地开花,在日常生活中也是非常常见的。为了帮助大家形成初步的理解,在进入代码世界之前,我们照例来看一段日常:
# # 14.1 生活中的观察者模式
周一刚上班,前端开发李雷就被产品经理韩梅梅拉进了一个钉钉群——“员工管理系统需求第 99 次变更群”。这个群里不仅有李雷,还有后端开发 A,测试同学 B。三位技术同学看到这简单直白的群名便立刻做好了接受变更的准备、打算撸起袖子开始干了。此时韩梅梅却说:“别急,这个需求有问题,我需要和业务方再确认一下,大家先各忙各的吧”。这种情况下三位技术同学不必立刻投入工作,但他们都已经做好了本周需要做一个新需求的准备,时刻等待着产品经理的号召。
一天过去了,两天过去了。周三下午,韩梅梅终于和业务方确认了所有的需求细节,于是在“员工管理系统需求第 99 次变更群”里大吼一声:“需求文档来了!”,随后甩出了"需求文档.zip"文件,同时@所有人。三位技术同学听到熟悉的“有人@我”提示音,立刻点开群进行群消息和群文件查收,随后根据群消息和群文件提供的需求信息,投入到了各自的开发里。上述这个过程,就是一个典型的观察者模式。
重点角色对号入座
观察者模式有一个“别名”,叫发布 - 订阅模式(之所以别名加了引号,是因为两者之间存在着细微的差异,下个小节里我们会讲到这点)。这个别名非常形象地诠释了观察者模式里两个核心的角色要素——“发布者”与“订阅者”。
在上述的过程中,需求文档(目标对象)的发布者只有一个——产品经理韩梅梅。而需求信息的接受者却有多个——前端、后端、测试同学,这些同学的共性就是他们需要根据需求信息开展自己后续的工作、因此都非常关心这个需求信息,于是不得不时刻关注着这个群的群消息提醒,他们是实打实的订阅者,即观察者对象。
现在我们再回过头来看一遍开头我们提到的略显抽象的定义:
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个目标对象,当这个目标对象的状态发生变化时,会通知所有观察者对象,使它们能够自动更新。
在我们上文这个钉钉群里,一个需求信息对象对应了多个观察者(技术同学),当需求信息对象的状态发生变化(从无到有)时,产品经理通知了群里的所有同学,以便这些同学接收信息进而开展工作:角色划分 --> 状态变化 --> 发布者通知到订阅者,这就是观察者模式的“套路”。
# # 14.2 在实践中理解定义
结合我们上面的分析,现在大家知道,在观察者模式里,至少应该有两个关键角色是一定要出现的——发布者和订阅者。用面向对象的方式表达的话,那就是要有两个类。
首先我们来看这个代表发布者的类,我们给它起名叫 Publisher。这个类应该具备哪些“基本技能”呢?大家回忆一下上文中的韩梅梅,韩梅梅的基本操作是什么?首先是拉群(增加订阅者),然后是@所有人(通知订阅者),这俩是最明显的了。此外作为群主&产品经理,韩梅梅还具有踢走项目组成员(移除订阅者)的能力。
// 定义发布者类
class Publisher {
constructor() {
this.observers = []
console.log('Publisher created')
}
// 增加订阅者
add(observer) {
console.log('Publisher.add invoked')
this.observers.push(observer)
}
// 移除订阅者
remove(observer) {
console.log('Publisher.remove invoked')
this.observers.forEach((item, i) => {
if (item === observer) {
this.observers.splice(i, 1)
}
})
}
// 通知所有订阅者
notify() {
console.log('Publisher.notify invoked')
this.observers.forEach((observer) => {
observer.update(this)
})
}
}
ok,搞定了发布者,我们一起来想想订阅者能干啥——其实订阅者的能力非常简单,作为被动的一方,它的行为只有两个——被通知、去执行(本质上是接受发布者的调用,这步我们在 Publisher 中已经做掉了)。既然我们在 Publisher 中做的是方法调用,那么我们在订阅者类里要做的就是方法的定义:
// 定义订阅者类
class Observer {
constructor() {
console.log('Observer created')
}
update() {
console.log('Observer.update invoked')
}
}
以上,我们就完成了最基本的发布者和订阅者类的设计和编写。在实际的业务开发中,我们所有的定制化的发布者/订阅者逻辑都可以基于这两个基本类来改写。比如我们可以通过拓展发布者类,来使所有的订阅者来监听某个特定状态的变化。仍然以开篇的例子为例,我们让开发者们来监听需求文档(prd)的变化:
// 定义一个具体的需求文档(prd)发布类
class PrdPublisher extends Publisher {
constructor() {
super()
// 初始化需求文档
this.prdState = null
// 韩梅梅还没有拉群,开发群目前为空
this.observers = []
console.log('PrdPublisher created')
}
// 该方法用于获取当前的prdState
getState() {
console.log('PrdPublisher.getState invoked')
return this.prdState
}
// 该方法用于改变prdState的值
setState(state) {
console.log('PrdPublisher.setState invoked')
// prd的值发生改变
this.prdState = state
// 需求文档变更,立刻通知所有开发者
this.notify()
}
}
作为订阅方,开发者的任务也变得具体起来:接收需求文档、并开始干活:
class DeveloperObserver extends Observer {
constructor() {
super()
// 需求文档一开始还不存在,prd初始为空对象
this.prdState = {}
console.log('DeveloperObserver created')
}
// 重写一个具体的update方法
update(publisher) {
console.log('DeveloperObserver.update invoked')
// 更新需求文档
this.prdState = publisher.getState()
// 调用工作函数
this.work()
}
// work方法,一个专门搬砖的方法
work() {
// 获取需求文档
const prd = this.prdState
// 开始基于需求文档提供的信息搬砖。。。
...
console.log('996 begins...')
}
}
下面,我们可以 new 一个 PrdPublisher 对象(产品经理),她可以通过调用 setState 方法来更新需求文档。需求文档每次更新,都会紧接着调用 notify 方法来通知所有开发者,这就实现了定义里所谓的:
目标对象的状态发生变化时,会通知所有观察者对象,使它们能够自动更新。
OK,下面我们来看看韩梅梅和她的小伙伴们是如何搞事情的吧:
// 创建订阅者:前端开发李雷
const liLei = new DeveloperObserver()
// 创建订阅者:服务端开发小A(sorry。。。起名字真的太难了)
const A = new DeveloperObserver()
// 创建订阅者:测试同学小B
const B = new DeveloperObserver()
// 韩梅梅出现了
const hanMeiMei = new PrdPublisher()
// 需求文档出现了
const prd = {
// 具体的需求内容
// ...
}
// 韩梅梅开始拉群
hanMeiMei.add(liLei)
hanMeiMei.add(A)
hanMeiMei.add(B)
// 韩梅梅发送了需求文档,并@了所有人
hanMeiMei.setState(prd)
# # 15. 行为型:观察者模式——面试真题手把手教学
观察者模式作为一个超高频考点,在设计模式中具有举足轻重的地位。
# # 15.1 Vue 数据双向绑定(响应式系统)的实现原理
解析
Vue 框架是热门的渐进式 JavaScript 框架。在 Vue 中,当我们修改状态时,视图会随之更新,这就是 Vue 的数据双向绑定(又称响应式原理)。数据双向绑定是 Vue 最独特的特性之一。如果读者没有接触过 Vue,强烈建议阅读 Vue 官方对响应式原理的介绍。此处我们用官方的一张流程图来简要地说明一下 Vue 响应式系统的整个流程:
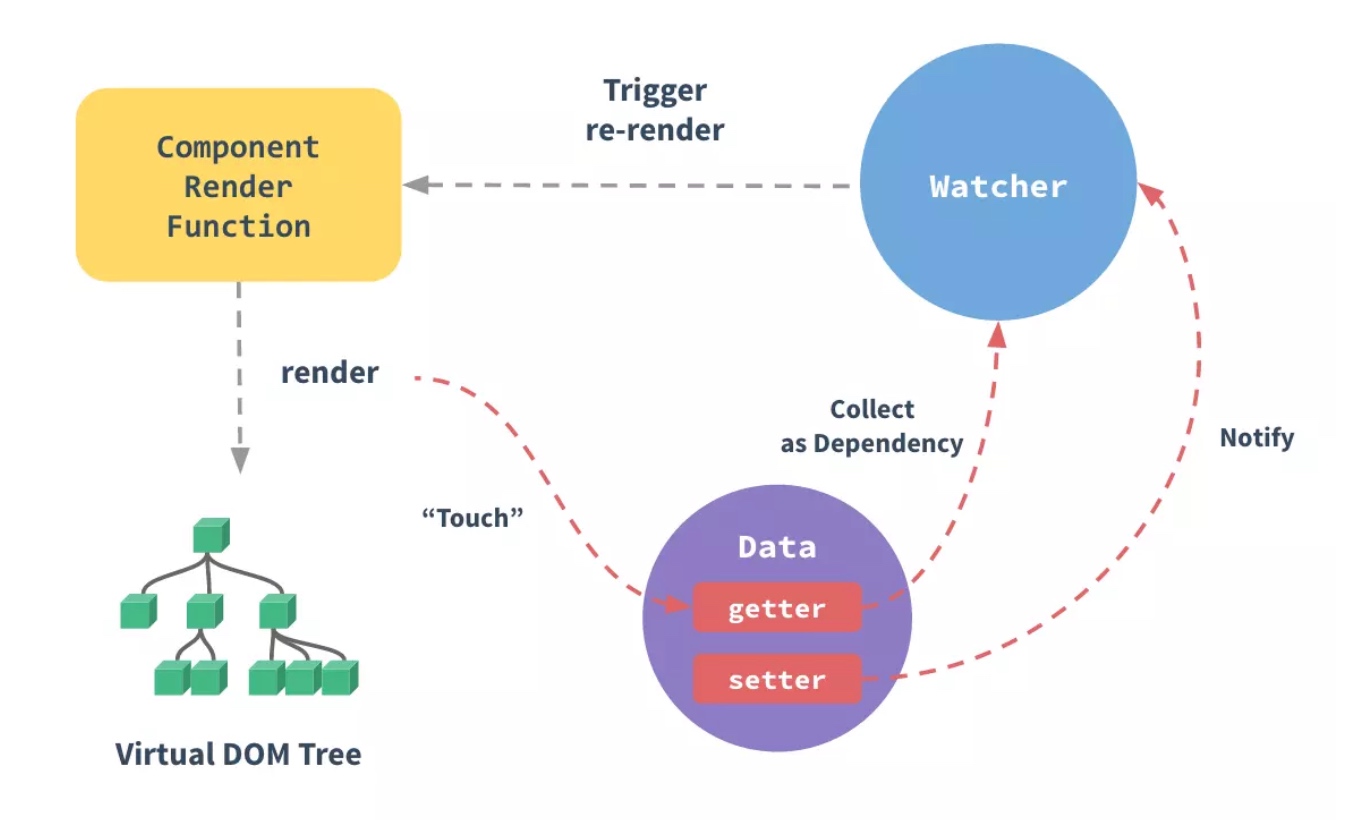
在 Vue 中,每个组件实例都有相应的 watcher 实例对象,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的 setter 被调用时,会通知 watcher 重新计算,从而致使它关联的组件得以更新——这是一个典型的观察者模式。这道面试题考察了受试者对 Vue 底层原理的理解、对观察者模式的实现能力以及一系列重要的 JS 知识点,具有较强的综合性和代表性。
在 Vue 数据双向绑定的实现逻辑里,有这样三个关键角色:
- observer(监听器):注意,此 observer 非彼 observer。在我们上节的解析中,observer 作为设计模式中的一个角色,代表“订阅者”。但在 Vue 数据双向绑定的角色结构里,所谓的 observer 不仅是一个数据监听器,它还需要对监听到的数据进行转发——也就是说它同时还是一个发布者。
- watcher(订阅者):observer 把数据转发给了真正的订阅者——watcher 对象。watcher 接收到新的数据后,会去更新视图。
- compile(编译器):MVVM 框架特有的角色,负责对每个节点元素指令进行扫描和解析,指令的数据初始化、订阅者的创建这些“杂活”也归它管~
这三者的配合过程如图所示:
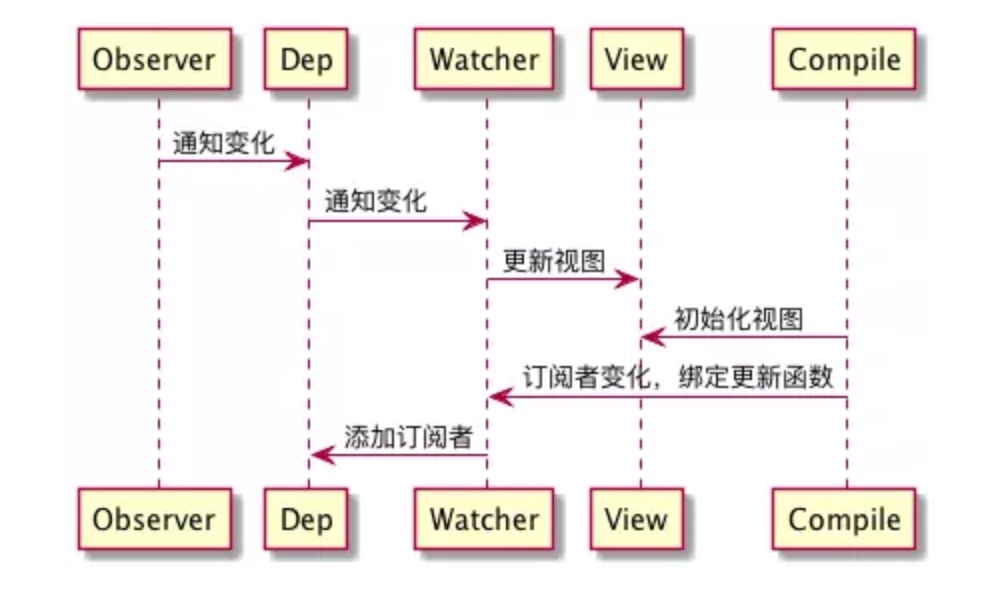
OK,实现方案搞清楚了,下面我们给整个流程中涉及到发布-订阅这一模式的代码来个特写:
# # 15.1.1 核心代码
实现 observer
首先我们需要实现一个方法,这个方法会对需要监听的数据对象进行遍历、给它的属性加上定制的 getter 和 setter 函数。这样但凡这个对象的某个属性发生了改变,就会触发 setter 函数,进而通知到订阅者。这个 setter 函数,就是我们的监听器:
// observe方法遍历并包装对象属性
function observe(target) {
// 若target是一个对象,则遍历它
if(target && typeof target === 'object') {
Object.keys(target).forEach((key)=> {
// defineReactive方法会给目标属性装上“监听器”
defineReactive(target, key, target[key])
})
}
}
// 定义defineReactive方法
function defineReactive(target, key, val) {
// 属性值也可能是object类型,这种情况下需要调用observe进行递归遍历
observe(val)
// 为当前属性安装监听器
Object.defineProperty(target, key, {
// 可枚举
enumerable: true,
// 不可配置
configurable: false,
get: function () {
return val;
},
// 监听器函数
set: function (value) {
console.log(`${target}属性的${key}属性从${val}值变成了了${value}`)
val = value
}
});
}
下面实现订阅者 Dep:
// 定义订阅者类Dep
class Dep {
constructor() {
// 初始化订阅队列
this.subs = []
}
// 增加订阅者
addSub(sub) {
this.subs.push(sub)
}
// 通知订阅者(是不是所有的代码都似曾相识?)
notify() {
this.subs.forEach((sub)=>{
sub.update()
})
}
}
现在我们可以改写 defineReactive 中的 setter 方法,在监听器里去通知订阅者了:
function defineReactive(target, key, val) {
const dep = new Dep()
// 监听当前属性
observe(val)
Object.defineProperty(target, key, {
set: (value) => {
// 通知所有订阅者
dep.notify()
}
})
}
# # 15.2 实现一个 Event Bus/ Event Emitter
Event Bus(Vue、Flutter 等前端框架中有出镜)和 Event Emitter(Node 中有出镜)出场的“剧组”不同,但是它们都对应一个共同的角色——全局事件总线。
全局事件总线,严格来说不能说是观察者模式,而是发布-订阅模式(具体的概念甄别我们会在下个小节着重讲)。它在我们日常的业务开发中应用非常广。
在 Vue 中使用 Event Bus 来实现组件间的通讯
Event Bus/Event Emitter 作为全局事件总线,它起到的是一个沟通桥梁的作用。我们可以把它理解为一个事件中心,我们所有事件的订阅/发布都不能由订阅方和发布方“私下沟通”,必须要委托这个事件中心帮我们实现。
在 Vue 中,有时候 A 组件和 B 组件中间隔了很远,看似没什么关系,但我们希望它们之间能够通信。这种情况下除了求助于 Vuex 之外,我们还可以通过 Event Bus 来实现我们的需求。
创建一个 Event Bus(本质上也是 Vue 实例)并导出:
const EventBus = new Vue()
export default EventBus
在主文件里引入 EventBus,并挂载到全局:
import bus from 'EventBus的文件路径'
Vue.prototype.bus = bus
订阅事件:
// 这里func指someEvent这个事件的监听函数
this.bus.$on('someEvent', func)
发布(触发)事件:
// 这里params指someEvent这个事件被触发时回调函数接收的入参
this.bus.$emit('someEvent', params)
大家会发现,整个调用过程中,没有出现具体的发布者和订阅者(比如上节的 PrdPublisher 和 DeveloperObserver),全程只有 bus 这个东西一个人在疯狂刷存在感。这就是全局事件总线的特点——所有事件的发布/订阅操作,必须经由事件中心,禁止一切“私下交易”!
下面,我们就一起来实现一个 Event Bus(注意看注释里的解析):
class EventEmitter {
constructor() {
// handlers是一个map,用于存储事件与回调之间的对应关系
this.handlers = {}
}
// on方法用于安装事件监听器,它接受目标事件名和回调函数作为参数
on(eventName, cb) {
// 先检查一下目标事件名有没有对应的监听函数队列
if (!this.handlers[eventName]) {
// 如果没有,那么首先初始化一个监听函数队列
this.handlers[eventName] = []
}
// 把回调函数推入目标事件的监听函数队列里去
this.handlers[eventName].push(cb)
}
// emit方法用于触发目标事件,它接受事件名和监听函数入参作为参数
emit(eventName, ...args) {
// 检查目标事件是否有监听函数队列
if (this.handlers[eventName]) {
// 如果有,则逐个调用队列里的回调函数
this.handlers[eventName].forEach((callback) => {
callback(...args)
})
}
}
// 移除某个事件回调队列里的指定回调函数
off(eventName, cb) {
const callbacks = this.handlers[eventName]
const index = callbacks.indexOf(cb)
if (index !== -1) {
callbacks.splice(index, 1)
}
}
// 为事件注册单次监听器
once(eventName, cb) {
// 对回调函数进行包装,使其执行完毕自动被移除
const wrapper = (...args) => {
cb.apply(...args)
this.off(eventName, wrapper)
}
this.on(eventName, wrapper)
}
}
在日常的开发中,大家用到 EventBus/EventEmitter 往往提供比这五个方法多的多的多的方法。但在面试过程中,如果大家能够完整地实现出这五个方法,已经非常可以说明问题了,因此楼上这个 EventBus 希望大家可以熟练掌握。学有余力的同学,推荐阅读FaceBook 推出的通用 EventEmiiter 库的源码 (opens new window) ,相信你会有更多收获。
# # 15.3 观察者模式与发布-订阅模式的区别是什么?
在面试过程中,一些对细节比较在意的面试官可能会追问观察者模式与发布-订阅模式的区别。这个问题可能会引发一些同学的不适,因为在大量参考资料以及已出版的纸质书籍中,都会告诉大家“发布-订阅模式和观察者模式是同一个东西的两个名字”。本书在前文的叙述中,也没有突出强调两者的区别。其实这两个模式,要较起真来,确实不能给它们划严格的等号。
为什么大家都喜欢给它们强行划等号呢?这是因为就算划了等号,也不影响我们正常使用,毕竟两者在核心思想、运作机制上没有本质的差别。但考虑到这个问题确实可以成为面试题的一个方向,此处我们还是单独拿出来讲一下。
回到我们上文的例子里。韩梅梅把所有的开发者拉了一个群,直接把需求文档丢给每一位群成员,这种发布者直接触及到订阅者的操作,叫观察者模式。但如果韩梅梅没有拉群,而是把需求文档上传到了公司统一的需求平台上,需求平台感知到文件的变化、自动通知了每一位订阅了该文件的开发者,这种发布者不直接触及到订阅者、而是由统一的第三方来完成实际的通信的操作,叫做发布-订阅模式。
相信大家也已经看出来了,观察者模式和发布-订阅模式之间的区别,在于是否存在第三方、发布者能否直接感知订阅者(如图所示)。
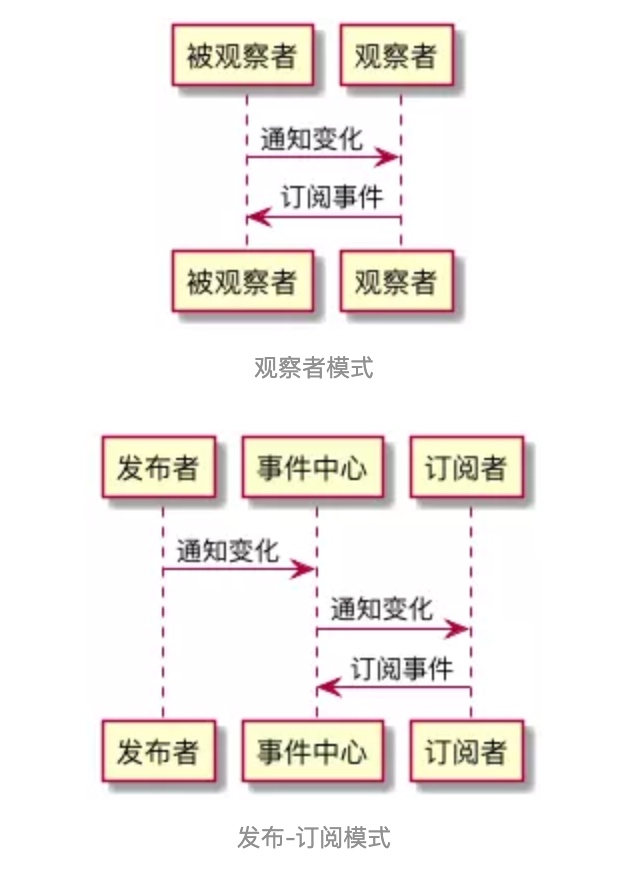
在我们见过的这些例子里,韩梅梅拉钉钉群的操作,就是典型的观察者模式;而通过 EventBus 去实现事件监听/发布,则属于发布-订阅模式。
# # 16. 行为型:迭代器模式——真·遍历专家
迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。 ——《设计模式:可复用面向对象软件的基础》
迭代器模式是设计模式中少有的目的性极强的模式。所谓“目的性极强”就是说它不操心别的,它就解决这一个问题——遍历。
# # 16.1 “公元前”的迭代器模式
遍历作为一种合理、高频的使用需求,几乎没有语言会要求它的开发者手动去实现。在 JS 中,本身也内置了一个比较简陋的数组迭代器的实现——Array.prototype.forEach。
通过调用 forEach 方法,我们可以轻松地遍历一个数组:
const arr = [1, 2, 3]
arr.forEach((item, index)=>{
console.log(`索引为${index}的元素是${item}`)
})
但 forEach 方法并不是万能的,比如下面这种场景:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>事件代理</title>
</head>
<body>
<a href="#">链接1号</a>
<a href="#">链接2号</a>
<a href="#">链接3号</a>
<a href="#">链接4号</a>
<a href="#">链接5号</a>
<a href="#">链接6号</a>
</body>
</html>
我想拿到所有的 a 标签,我可以这样做:
const aNodes = document.getElementsByTagName('a')
console.log('aNodes are', aNodes)
我想取其中一个 a 标签,可以这样做:
const aNode = aNodes[i]
在这个操作的映衬下,aNodes 看上去多么像一个数组啊!但当你尝试用数组的原型方法去遍历它时:
aNodes.forEach((aNode, index){
console.log(aNode, index)
})
你发现报错了: 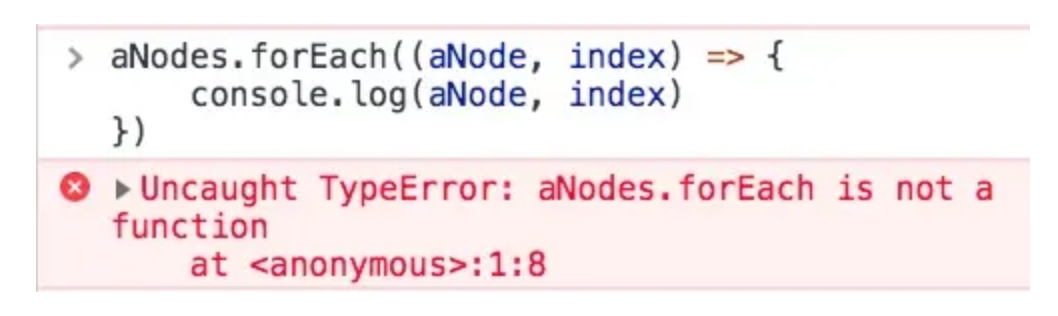
震惊,原来这个 aNodes 是个假数组!准确地说,它是一个类数组对象,并没有为你实现好用的 forEach 方法。也就是说,要想实现类数组的遍历,你得另请高明。
现在问题就出现了:普通数组是不是集合?是!aNodes 是不是集合?是!同样是集合,同样有遍历需求,我们却要针对不同的数据结构执行不同的遍历手段,好累!再回头看看迭代器的定义是什么——遍历集合的同时,我们不需要关心集合的内部结构。而 forEach 只能做到允许我们不关心数组这一种集合的内部结构,看来想要一套统一的遍历方案,我们非得请出一个更强的通用迭代器不可了。
这个小节的标题定语里有三个字“公元前”,这个“公元前”怎么定义呢?其实它说的就是 ES 标准内置迭代器之前的那些日子——差不多四五年之前,彼时还没有这么多轮子,jQuery 风头正盛。当时面试可不问什么 Vue 原理、React 原理、Webpack 这些,当时问的最多的是你读过 jQuery 源码吗?答读过,好,那咱们就有的聊了。答没有?fine,看来你只是个调包侠,回见吧——因为前端的技术点在那时还很有限,所以可考察的东西也就这么点,读 jQuery 源码的程序员和不读 jQuery 源码的程序员在面试官眼里有着质的区别。但这也从一个侧面反映出来,jQuery 这个库其实是非常优秀的,至少 jQuery 里有太多优秀的设计模式可以拿来考考你。就包括咱们当年想用一个真·迭代器又不想自己搞的时候,也是请 jQuery 实现的迭代器来帮忙:
<script src="https://cdn.bootcss.com/jquery/3.3.0/jquery.min.js" type="text/javascript"></script>
借助 jQuery 的 each 方法,我们可以用同一套遍历规则遍历不同的集合对象:
const arr = [1, 2, 3]
const aNodes = document.getElementsByTagName('a')
$.each(arr, function (index, item) {
console.log(`数组的第${index}个元素是${item}`)
})
$.each(aNodes, function (index, aNode) {
console.log(`DOM类数组的第${index}个元素是${aNode.innerText}`)
})
输出结果完全没问题:
 当然啦,遍历 jQuery 自己的集合对象也不在话下:
当然啦,遍历 jQuery 自己的集合对象也不在话下:
const jQNodes = $('a')
$.each(jQNodes, function (index, aNode) {
console.log(`jQuery集合的第${index}个元素是${aNode.innerText}`)
})
输出结果仍然没问题:
 可以看出,jQuery 的迭代器为我们统一了不同类型集合的遍历方式,使我们在访问集合内每一个成员时不用去关心集合本身的内部结构以及集合与集合间的差异,这就是迭代器存在的价值~
可以看出,jQuery 的迭代器为我们统一了不同类型集合的遍历方式,使我们在访问集合内每一个成员时不用去关心集合本身的内部结构以及集合与集合间的差异,这就是迭代器存在的价值~
# # 16.2 ES6 对迭代器的实现
在“公元前”,JS 原生的集合类型数据结构,只有 Array(数组)和 Object(对象);而 ES6 中,又新增了 Map 和 Set。四种数据结构各自有着自己特别的内部实现,但我们仍期待以同样的一套规则去遍历它们,所以 ES6 在推出新数据结构的同时也推出了一套统一的接口机制——迭代器(Iterator)。
ES6 约定,任何数据结构只要具备 Symbol.iterator 属性(这个属性就是 Iterator 的具体实现,它本质上是当前数据结构默认的迭代器生成函数),就可以被遍历——准确地说,是被 for...of...循环和迭代器的 next 方法遍历。 事实上,for...of...的背后正是对 next 方法的反复调用。
在 ES6 中,针对 Array、Map、Set、String、TypedArray、函数的 arguments 对象、NodeList 对象这些原生的数据结构都可以通过 for...of...进行遍历。原理都是一样的,此处我们拿最简单的数组进行举例,当我们用 for...of...遍历数组时:
const arr = [1, 2, 3]
const len = arr.length
for(item of arr) {
console.log(`当前元素是${item}`)
}
之所以能够按顺序一次一次地拿到数组里的每一个成员,是因为我们借助数组的 Symbol.iterator 生成了它对应的迭代器对象,通过反复调用迭代器对象的 next 方法访问了数组成员,像这样:
const arr = [1, 2, 3]
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 对迭代器对象执行next,就能逐个访问集合的成员
iterator.next()
iterator.next()
iterator.next()
丢进控制台,我们可以看到 next 每次会按顺序帮我们访问一个集合成员:
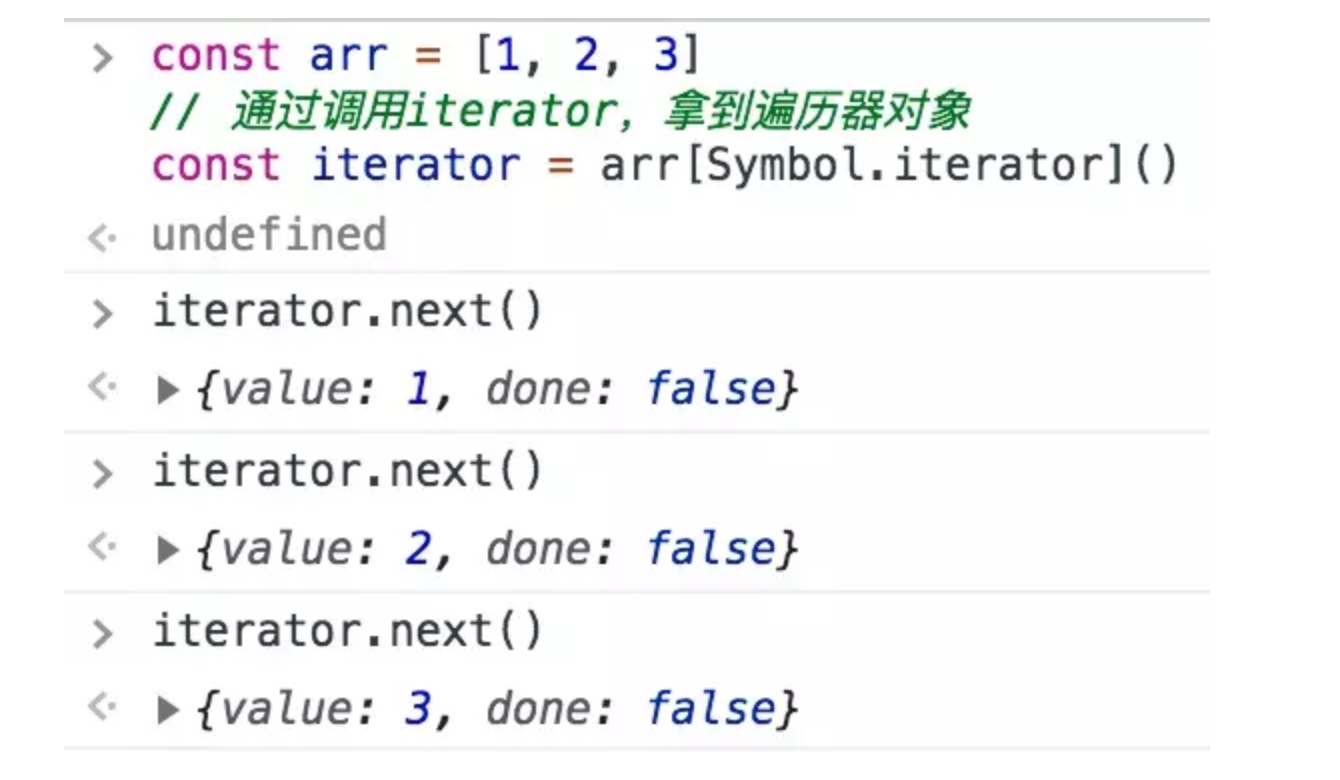
而 for...of...做的事情,基本等价于下面这通操作:
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 初始化一个迭代结果
let now = { done: false }
// 循环往外迭代成员
while(!now.done) {
now = iterator.next()
if(!now.done) {
console.log(`现在遍历到了${now.value}`)
}
}
可以看出,for...of...其实就是 iterator 循环调用换了种写法。在 ES6 中我们之所以能够开心地用 for...of...遍历各种各种的集合,全靠迭代器模式在背后给力。
# # 16.3 一起实现一个迭代器生成函数吧!
楼上我们说迭代器对象全凭迭代器生成函数帮我们生成。在 ES6 中,实现一个迭代器生成函数并不是什么难事儿,因为 ES6 早帮我们考虑好了全套的解决方案,内置了贴心的生成器(Generator)供我们使用:
// 编写一个迭代器生成函数
function *iteratorGenerator() {
yield '1号选手'
yield '2号选手'
yield '3号选手'
}
const iterator = iteratorGenerator()
iterator.next()
iterator.next()
iterator.next()
丢进控制台,不负众望:

写一个生成器函数并没有什么难度,但在面试的过程中,面试官往往对生成器这种语法糖背后的实现逻辑更感兴趣。下面我们要做的,不仅仅是写一个迭代器对象,而是用 ES5 去写一个能够生成迭代器对象的迭代器生成函数(解析在注释里):
// 定义生成器函数,入参是任意集合
function iteratorGenerator(list) {
// idx记录当前访问的索引
var idx = 0
// len记录传入集合的长度
var len = list.length
return {
// 自定义next方法
next: function() {
// 如果索引还没有超出集合长度,done为false
var done = idx >= len
// 如果done为false,则可以继续取值
var value = !done ? list[idx++] : undefined
// 将当前值与遍历是否完毕(done)返回
return {
done: done,
value: value
}
}
}
}
var iterator = iteratorGenerator(['1号选手', '2号选手', '3号选手'])
iterator.next()
iterator.next()
iterator.next()
此处为了记录每次遍历的位置,我们实现了一个闭包,借助自由变量来做我们的迭代过程中的“游标”。
运行一下我们自定义的迭代器,结果符合预期:

- 本文链接: https://mrgaogang.github.io/javascript/deep/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 许可协议。转载请注明出处!